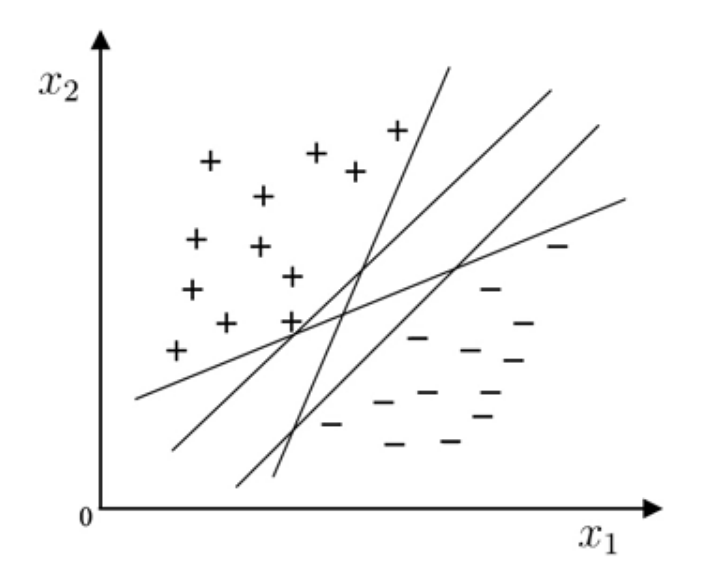
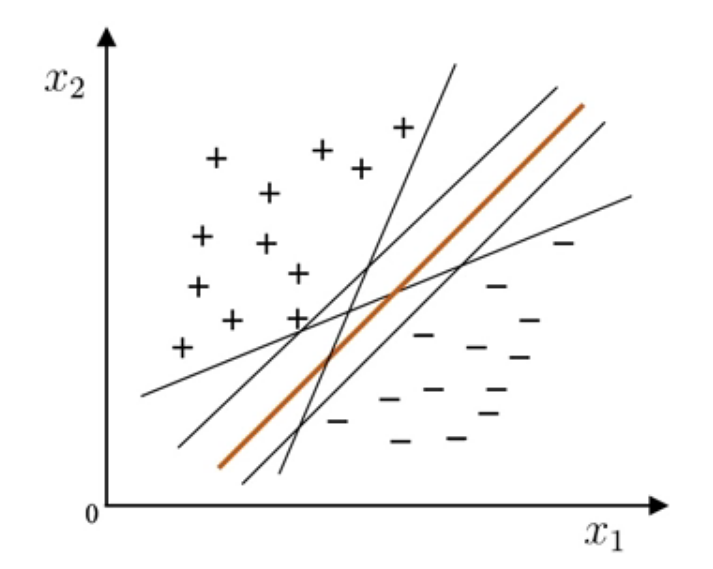
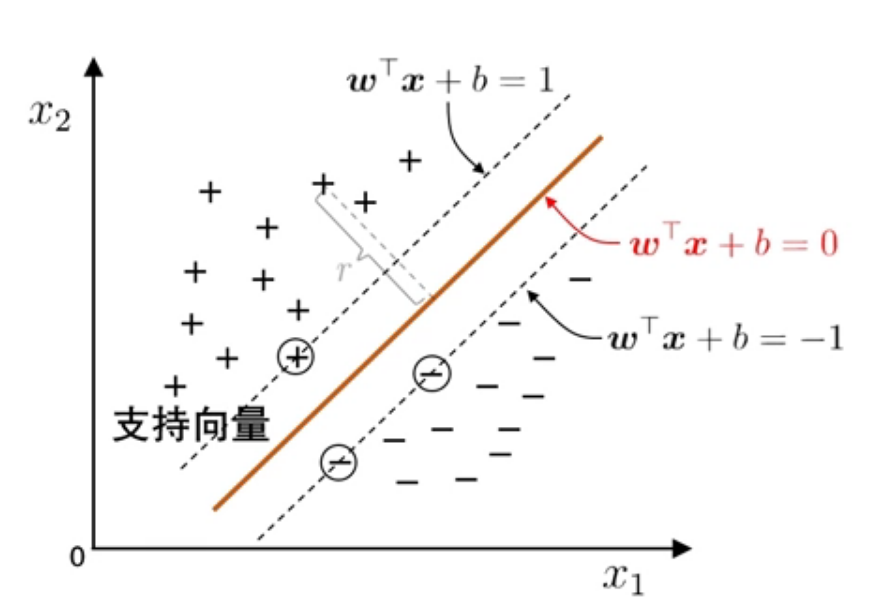
每日一题-20250811
Leetcode
2438. 二的幂数组中查询范围内的乘积/第 89 场双周赛 Q2/Rating 1610
- 位运算
- 前缀和
- 快速幂
考虑到 ,所以可以对指数做前缀和,然后快速幂求解。
也可以不做前缀和,每次进行求和,然后快速幂求解。
1 | MOD = 10 ** 9 + 7 |
2438. 二的幂数组中查询范围内的乘积/第 89 场双周赛 Q2/Rating 1610
- 位运算
- 前缀和
- 快速幂
考虑到 ,所以可以对指数做前缀和,然后快速幂求解。
也可以不做前缀和,每次进行求和,然后快速幂求解。
1 | MOD = 10 ** 9 + 7 |
869. 重新排序得到 2 的幂/第 93 场周赛 Q2/Rating 1505
- 排序
- 哈希
考虑到 ,可以直接枚举这个范围内的所有 的幂进行哈希,只需要判断给定数字的哈希是否存在即可。
1 | p = [sorted(str(1 << i)) for i in range(0, 31)] |
- 思维
- 差分
- 前缀和
- 正难则反
直接计算原问题是困难的,但是对于已经出现过的数,维护如何让序列的 是容易的:
808. 分汤/第 78 场周赛 Q3/Rating 2397
- 概率 dp
- 诈骗
考虑朴素概率 dp: 表示汤 剩余 ml 且汤 剩余 ml 时的答案。
显然有状态转移:
边界情况:
1 | class Solution: |
此时并没有考虑 的数据范围,朴素的状态转移显然会超时。
此处我们研究一个名为 Cymbol 的语言,是 C 语言的子集(代码附后):
这样的文法有几个问题:
二义性:一段程序可以有多种解释方法。
1 | stat: 'if' expr 'then' stat |
假设此时有这样的程序:if a then if b then c else d,会出现二义性:
if a then if b then c else d;if a then if b then c else d。这种语法歧义被称为“悬空的 else”。
如何修改这样有二义性的文法?
我们将文法修改为:
1 | stat: matched_stat | open stat ; |
改造后的文法实现了第一种解释。
为什么?
证明留做习题(
但是注意到,通过 ANTLR4 测试改造前的文法,发现同样实现的是第一种解释,并无二义性。原因是 ANTLR4 会按照从上向下的顺序分配优先级,越往上的优先级越高,所以这种实现也是正确的。
运算符的结合性带来的二义性:
1 | expr: expr '*' expr |
对于此文法,1-2-3 会被解释为 (1-2)-3 或 1-(2-3):
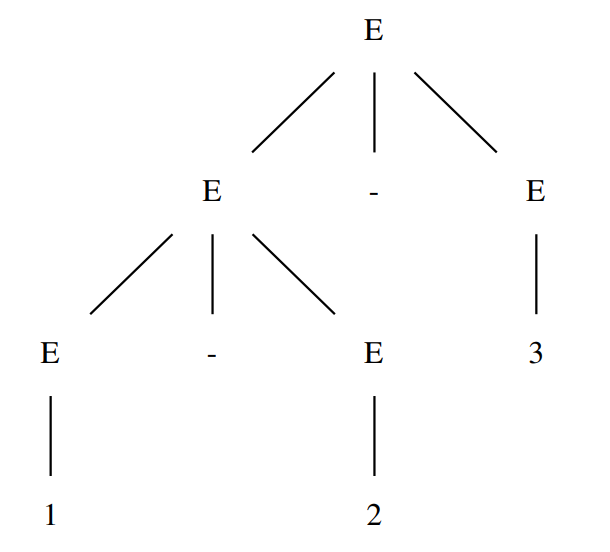
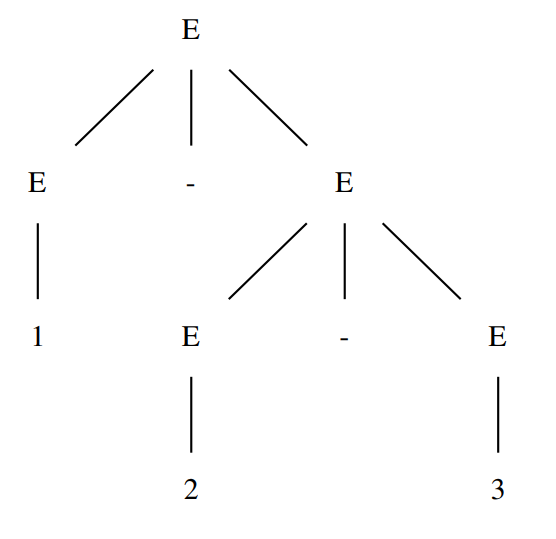
在 ANTLR4 中,如果未明确运算符是左结合还是右结合,默认左结合,即上述表达式被解释为 (1-2)-3。
如果想指定右结合,可以在语句前加入 <assoc = right>,如:
1 | expr: '!' expr |
考虑前缀运算符,这东西不带来歧义,只有一种解析方式,即右结合;后缀运算符只能左结合。
运算符的优先级带来的二义性:
1 | expr: expr '*' expr |
当一个运算符优先级更高时,在解析树中的深度会更深。在 ANTLR4 中这样写已经可以处理优先级的问题,因为写在前面的优先级更高。
如果不得已非要处理这种情况,可以通过两种方法:
改为左递归(左结合):
1 | expr: expr '-' term |
如此,对于一个语法单元 expr,只会被左侧的 expr 调用递归,这被称为左递归文法,这样限制了文法只能被左结合的方式进行解释。
由于乘号优先级更高,所以要把乘号放在右侧,等待 expr 被解释完成后再进行解释。
左递归文法:e -> e - t -> e - t - t -> ...
改为右递归:
1 | expr: term expr_prime; |
expr 表示的内容依然为 term-term-term-...,不同的是,通过引入新的语法单元 prime,expr 生成的方式为先生成一个 term,再不断生成 -term 序列,这样就是右递归文法了。
右递归文法:e -> tEP -> t - tEP -> t - t - tEP -> ...
函数调用图表示的是函数之间的调用关系。
获取函数名有两个时机:
functionDecl 时,可以获得当前进入的函数名;functionCall 时,即找到一个 expr 表示的是 ID '(' exprList? ')' 时,我们就可以得到被调用函数的函数名(即 ID)。只要在图中将这两个函数名连边即可。
约定 表示点集为 ,边集为 的图,若无特殊说明,则 ,。
若干基本定义:
当 dfs 一个图时,按照 dfs 的顺序可以构造出一个树结构,被称为 DFS 树。
有向图的 dfs 树主要有四种边:
卷积神经网络(CNN)是一个专门用于图像处理的神经网络。
下面的讨论都是基于假设所有图像的尺寸是固定的,不会突然出现大小不一致的图片。
图像识别模型的输入是一张图片,输出是一个独热(one-hot)的向量 ,只有模型认为最有可能的类别为 1,其余都为 0。这个向量的长度表示着当前模型能识别出的种类数目。模型在输出独热向量之前,会先通过 Softmax 输出一个向量 ,我们希望 和 的交叉熵尽可能地小。
对于输入,人眼看到的是一张三维的图像,计算机看到的是什么呢?计算机看到的是一个三维的张量(粗略的认为是维度大于 2 的矩阵),一维代表图片的宽,一维代表图片的高,另一维代表这张图片通道的个数,当给定一张彩色图片时,图片通道数为 3,分别表示 R、G 和 B。
当我们把一张图片“拉直”成一个向量之后,就可以放到神经网络中让它进行识别分类了。
目前为止,我们只学到了全连接神经网络,如果输入是一个 的向量,第二层的神经元有 1000 个,那么将会有 个权重,这是一个非常巨大的数,计算过程会非常缓慢,同时过拟合的风险也会增加。
考虑图像识别的特性,我们并不需要每一个神经元和输入的每一维都有一个权重,即全连接是不必要的。