Linear Regression
Model representation
线性回归的预测方程可以写为
hθ(x)=i=0∑nθixi
其中规定 x0=1。
若令
θ=⎣⎢⎢⎢⎢⎡θ0θ1⋮θn⎦⎥⎥⎥⎥⎤∈Rn+1,X=⎣⎢⎢⎢⎢⎡x0x1⋮xn⎦⎥⎥⎥⎥⎤∈Rn+1
则预测方程可以写为
hθ(x)=θTX
Cost function
线性回归的代价函数为
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
此时梯度下降式成为
θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
Feature Scaling
所谓的特征缩放,其目的是使所有的特征都能处在一个基本一致的区间内,不会因为某个特征的值都过大或过小而对计算造成误差或难以计算。(即归一化、标准化、正则化)
例如对于一个二维的数据,其中有一维数据比另一维数据大很多,这可能会导致在梯度下降时过分缓慢,出现反复来回震荡的问题。如果将数据进行归一化,可以证明,梯度下降可以找到一条更快地找到全局最小的路径。
归一化希望使所有的特征都能在 approximately −1≤xi≤1 的范围内,只要他们足够接近,梯度下降法就会正常地工作。
Mean Normalization
均值归一化是将所有的值 xi 都减去其平均值 μi,再除以数据的范围 max−min
xi=max−minxi−μi
假设 x1∈[0,2000],那么对于 x1 的均值归一化为 x1=2000x1−1000,如此处理后所有特征都会被缩放在 [−0.5,0.5] 这一区间内。
min-max Normalization
min-max 归一化是对均值归一化的改进,其公式为
xi=max−minxi−min
其中 max 为这组特征的最大值,min 为这组特征的最小值。
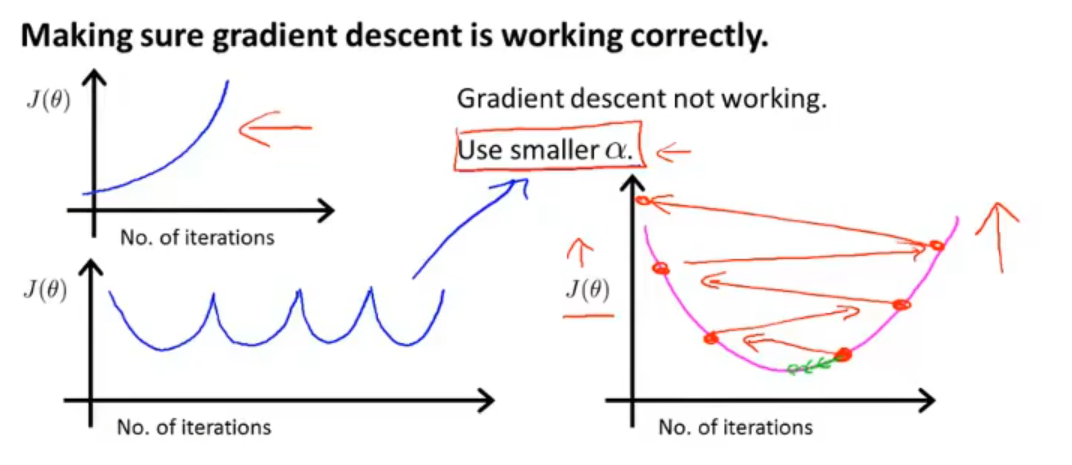
Learning Rate

Features and polynomial regression
有时不必直接使用给出的特征构造模型,可以新定义一个特征,如此可能会得到一个更好的模型。
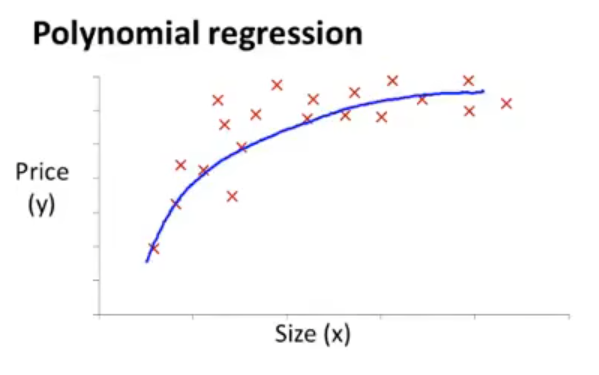
关系不一定是线性的,有时需要通过高维进行拟合
如果想使用线性回归的话,可以令 xi=xk,如此便可得到一个线性回归形式的式子,这样的话归一化变得更为重要。
特征选定可以根据实际情况来改,训练后看测试结果是否符合
Normal equation
Normal equation 是一个计算参数 θ 的解析解法,使得我们不用通过梯度下降法这一迭代算法进行计算。
以 1D 举例:J(θ)=aθ2+bθ+c,θ∈R,找到这个函数的最小值只需求此函数的驻点(即一阶导数的零点)即可。
但当 θ∈Rn+1 时,J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2,找到这个函数的最小值相当于求满足
∂θj∂J(θ)=0, j=0,1,…,m
的一组 θ 值。
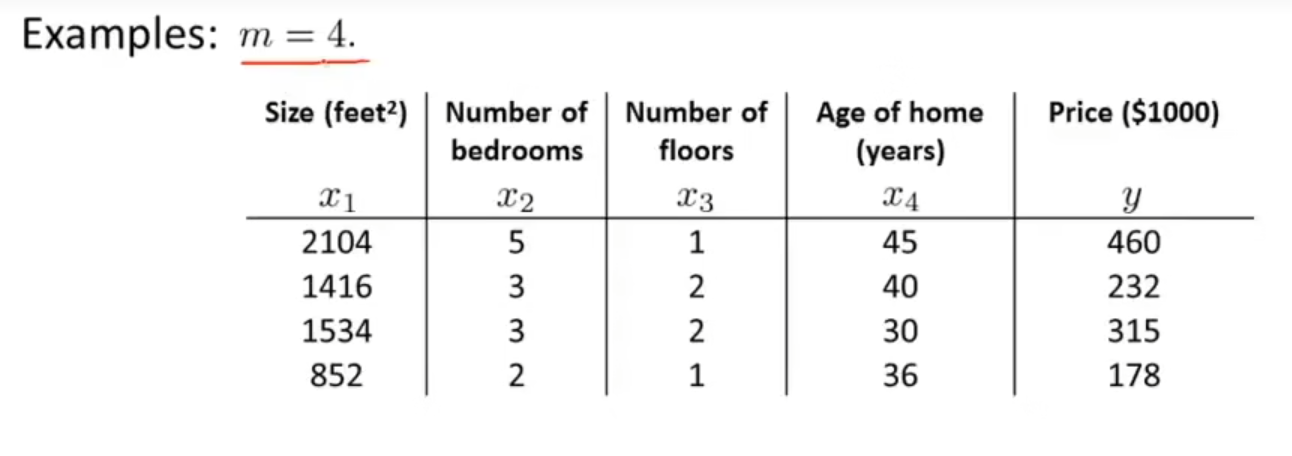
通过数据构造一个矩阵
X=⎣⎢⎢⎢⎡11112104141615348525332122145403036⎦⎥⎥⎥⎤
和一个向量
y=⎣⎢⎢⎢⎡460232315178⎦⎥⎥⎥⎤
可以发现,X 为一个 m×(n+1) 的矩阵,y 是一个 m 维向量,其中 m 为数据集大小,n 为特征变量数。
由于在线性回归中,我们希望确定 ω,b 使得
f(xi)=ωxi+b≃yi
此时我们可以通过令均方误差最小化得到 ω,b 的解 ω∗,b∗
(ω∗,b∗)=arg(ω,b)mini=1∑m(f(xi)−yi)2=arg(ω,b)mini=1∑m(yi−ωxi−b)2=E(ω,b)
令上式分别对 ω 和 b 求导可得
∂ω∂E∂b∂E=2(ωi=1∑mxi2−i=1∑m(yi−b)xi)=2(mb−i=1∑m(yi−ωxi))
令上述两式分别为 0,可得 ω 和 b 最优解的闭式解
ωb=i=1∑mxi2−m1(i=1∑mxi)2i=1∑myi(xi−x)=m1i=1∑m(yi−ωxi)
其中 x 为 x 的均值。
更一般地,当特征不唯一时,我们的 ω 将是一个矩阵,令 w^∗=(ω; b),则其解为
w^∗=w^argmin(y−Xw^)T(y−Xw^)
令 Ew^=(y−Xω^)T(y−Xω^),对 ω^ 求导得到
∂w^∂Ew^=2XT(Xw^−y)
令上式为 0 即可得到 w^ 最优解的闭式解。当 XTX 为满秩矩阵时可得 θ=(XTX)−1XTy。
于是我们得到 θ=(XTX)−1XTy,这个 θ 就是使代价函数最小的 θ。
更普适地,令 X=⎣⎢⎢⎢⎢⎢⎡11⋮1⋯⋯⋮⋯(x(1))T(x(2))T⋮(x(m))T⋯⋯⋮⋯⎦⎥⎥⎥⎥⎥⎤(m×(n+1)),y=⎣⎢⎢⎢⎢⎡y(1)y(2)⋮y(n)⎦⎥⎥⎥⎥⎤,则 θ=(XTX)−1XTy。
如果直接使用正规方程法的话,没有必要对所有特征做特征缩放,如果使用梯度下降则必须对所有特征做特征缩放。

由于矩阵乘法是 O(n3) 的,在特征较多时会很慢,此时可以考虑梯度下降。
