Neural Networks
Non-linear hypotheses
在特征较少时,对于一个边界较为复杂的数据集中,我们可以使用逻辑回归,通过构造一个多项式来拟合决策边界,但在特征较多时,逻辑回归便显得较为繁杂,我们很难构造一个合适的多项式来较好的拟合其决策边界。
例如,当有 100 个特征时,如果我们只构造一个二次多项式,那么这个多项式最多会有 (2100) 个,也就是说,二次项会有 O(n2) 个,极易导致过拟合的情况出现,同时也会出现计算量过大的问题。
如果我们继续将多项式的次数提高,那么会有 O(n3) 个三次项,O(n4) 个四次项……这对我们的模型构造和计算都是不可承受的。
考虑一个计算机视觉中的问题:如何让计算机识别出一辆汽车?人眼对于识别一辆汽车轻而易举,但对于计算机,它得到的可以是一个亮度的矩阵,也可以是一个颜色的矩阵等等。
在训练这样的模型时,我们需要做的是提供两个带标签的数据集,其中一个表示这里面的数据全都是车,另一个表示全都不是车。在分类器训练完成后,如果给定一个汽车的图片并要求它分类,理想状态下分类器可以识别出这是一辆汽车。
具体地,我们假设在每个图片的相同位置取两个像素点,并将其传入分类器中,如下图所示:
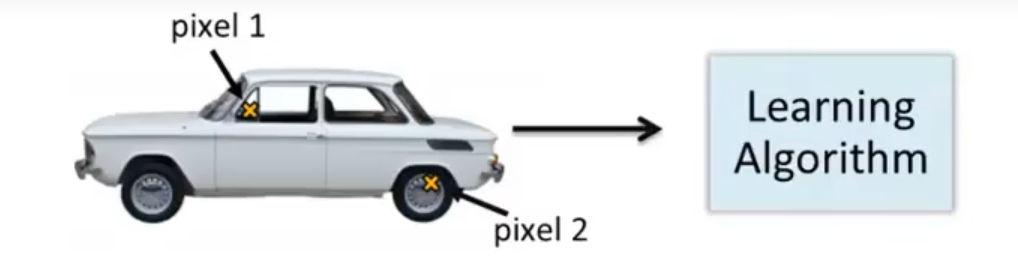
对于是汽车的样本和不是汽车的样本,我们可以发现,存在一个非线性的决策边界使得这两类可以被分开:
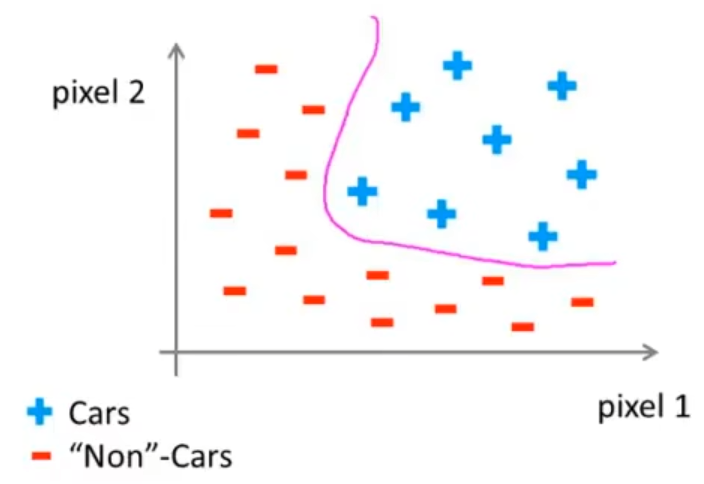
现在我们考虑每个样本的特征数量,假设每个样本都是一张 50×50 的图片,那么就有 2500 个像素点,特征数量 n=2500,这是在只使用灰度图片的情况下,如果我们使用彩色图片,这个数字将会变为 2500×3=7500。
此时如果使用逻辑回归的话极大可能会出现过拟合的问题,这就引出了我们的神经网络模型。
Model representation
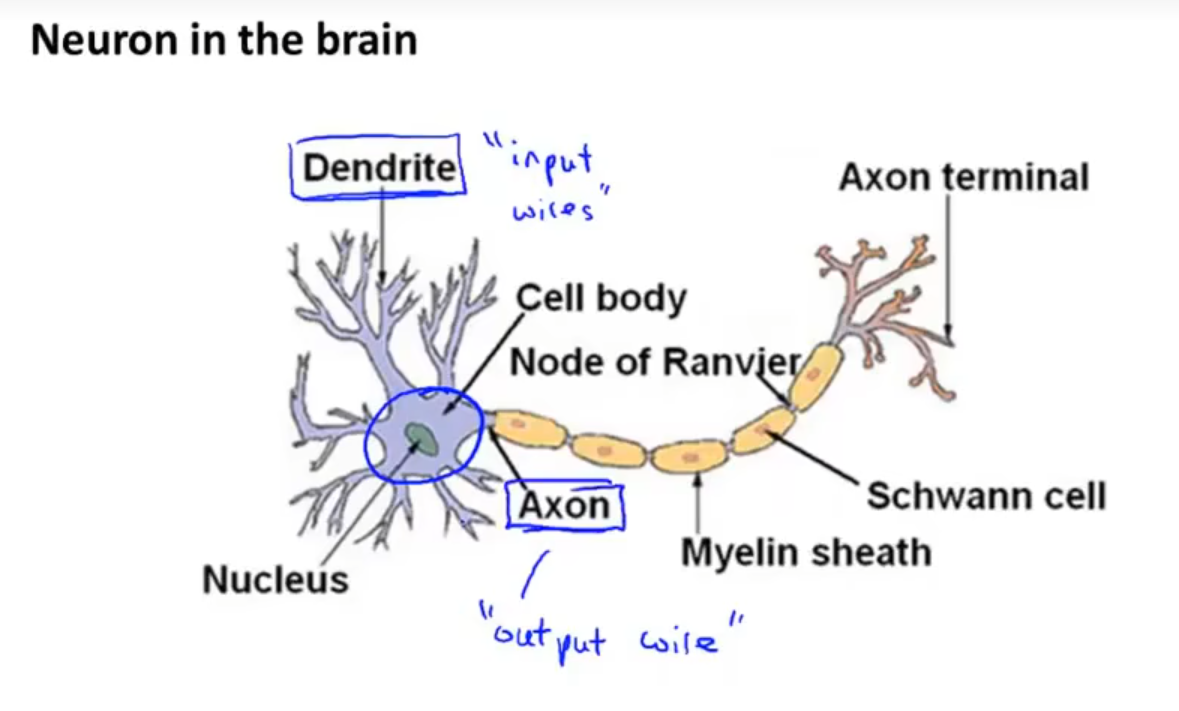
可以认为一个神经元是通过树突接收信号,进行一系列计算后通过轴突输出信号。
最简单的一个神经元模型如图所示:
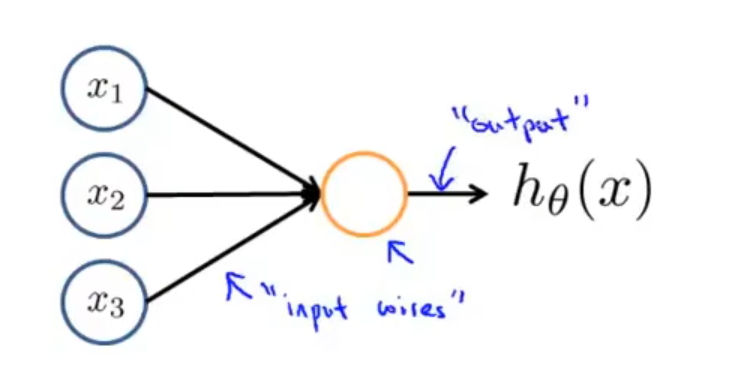
这表示有三个输入,通过神经元计算出 hθ(x)=1+e−θTx1 的值并输出。此处的 hθ(x) 被称为 Sigmoid 激活函数,θ 一般被称作权重或参数。注意,有时也会加上一个输入 x0,被称作偏置单元,但由于其值永远为 0,故可以省略。
神经网络实际上是一组神经元连接在一起的集合。
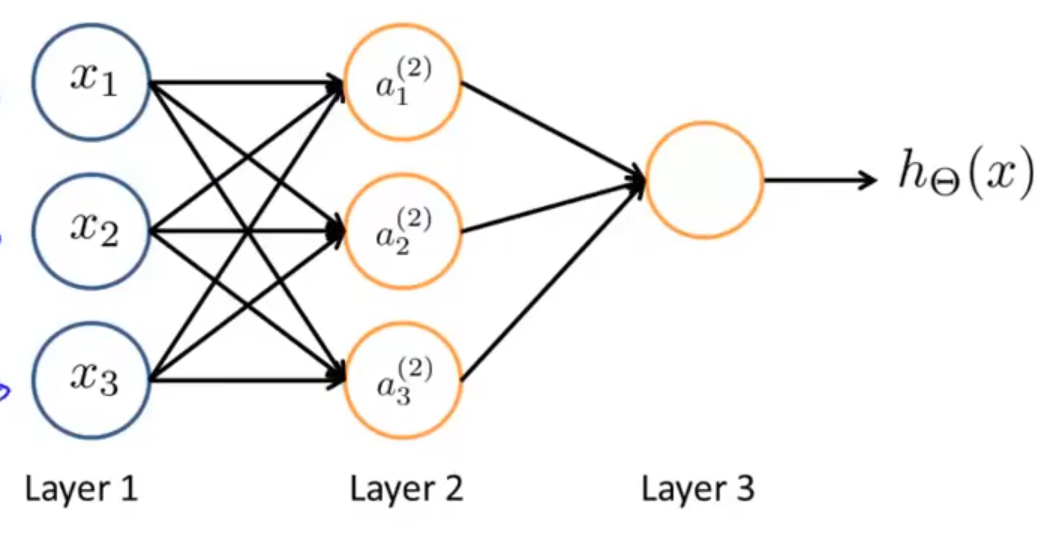
第一层被称作输入层,最后一层被称作输出层,中间的第二层被称作隐藏层,隐藏层可以不止一层,非输入层和输出层的层都被称为隐藏层。
下面对神经网络中一些记号进行解释:
- ai(j) 表示第 j 层第 i 个神经元或单元的激活项,激活项是指由一个具体的神经元计算并输出的值;
- Θ(j) 表示控制从第 j 层到第 j+1 层的映射的权重矩阵。
对于此图所表示的神经网络,几个激活项的值分别为:
a1(2)=g(Θ10(1)x0+Θ11(1)x1+Θ12(1)x2+Θ13(1)x3)
a2(2)=g(Θ20(1)x0+Θ21(1)x1+Θ22(1)x2+Θ23(1)x3)
a3(2)=g(Θ30(1)x0+Θ31(1)x1+Θ32(1)x2+Θ33(1)x3)
hΘ(x)=a1(3)=g(Θ10(2)a0(2)+Θ11(2)a1(2)+Θ12(2)a2(2)+Θ13(2)a3(2))
其中,g(x)=1+e−x1 为 sigmoid 函数。如果第 j 层有 sj 个单元,j+1 层有 sj+1 个单元,则 Θ(j) 的维数为 sj+1×(sj+1)。
通过观察上面 a1(2)、a2(2) 和 a1(2) 三式,我们不难将其写做一个矩阵相乘的形式:
g⎝⎜⎜⎜⎛⎣⎢⎢⎢⎡x0x1x2x3⎦⎥⎥⎥⎤×⎣⎢⎡Θ10Θ20Θ30Θ11Θ21Θ31Θ12Θ22Θ32Θ13Θ23Θ33⎦⎥⎤T⎠⎟⎟⎟⎞=⎣⎢⎡a1a2a3⎦⎥⎤
上式也可写作:z(2)=Θ(1)xa(2)=g(z(2))
如果把输入 x 看做是第一层的激活项 a(1),则整个式子可以写作
{z(i+1)=Θ(i)a(i)a(i+1)=g(z(i+1))
注意,这其中的偏置单元 a0 本身不会在输入中给出,一般默认其为 1。
设输出层为第 n 层,则hΘ(x)=a(n)=g(z(n)),这个计算过程被称为前向传播。
在神经网络中,信息从上一个神经元直接流转到下一个神经元,直到输出,依据每一个神经元的输入并根据相应规则可以计算出输出,最终得到在当前参数下的损失函数的过程,称为前向传播。
这个神经网络相当于一个多层的逻辑回归模型,其将上一层数据的逻辑回归结果作为输入传入下一层中。
Example and intuitions
考虑一个异或问题,其中输入特征为 x1,x2 两个,其取值只能为 0 或 1,则正样本和负样本的分布如下图所示:
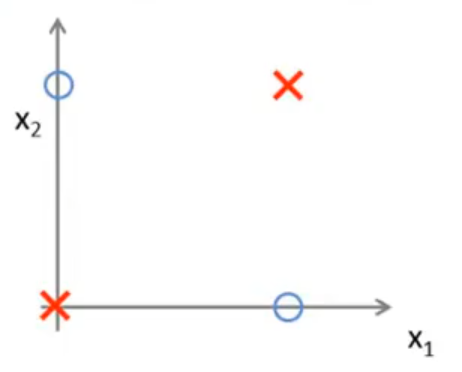
对于该分类问题,预测函数显然为 y=x1⨁x2,其中 ⨁ 表示异或,但我们希望构造一个神经网络,显然神经网络中我们是无法使用异或运算的,于是我们考虑构造一个非线性函数来拟合异或的结果。
首先,我们考虑构造一个能进行 AND 运算的神经元,
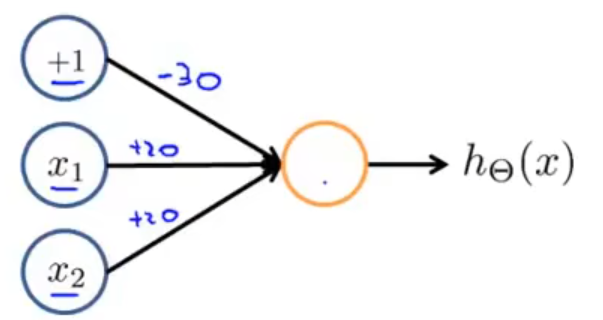
对于该神经元,我们得到的输出 hΘ(x)=g(20x1+20x2−30),我们没有显式的给出权重矩阵 Θ,但把每个单元对应的权重标在了图中。事实上,此处的权重并不一定要取这三个值,只需要保证最后得到的结果正确即可。下表展示了该神经元的计算结果:
| x1 |
x2 |
hΘ(x) |
| 0 |
0 |
g(−30)≈0 |
| 0 |
1 |
g(−10)≈0 |
| 1 |
0 |
g(−10)≈0 |
| 1 |
1 |
g(10)≈1 |
通过上表我们可以得到 hΘ(x)≈x1ANDx2。
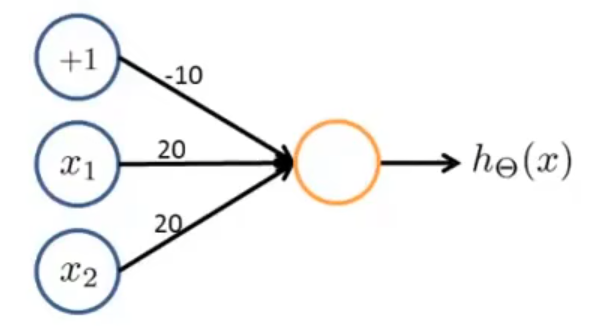
此神经元实现了 OR 的功能,计算结果略去。
接下来我们考虑如何实现一个计算 x1XNORx2(同或)的神经网络。
考虑逻辑推导同或,由于 A⨁B=AB+AB,由德摩根律得 AXNORB=(AB+AB)=AB+AB。
根据此,我们可以构造一个神经网络:
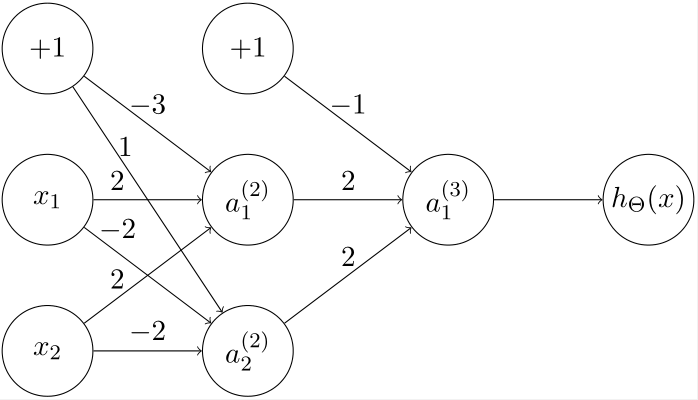
通过简单的计算我们得到,a1(2) 计算得到的结果是 AB,a2(2) 计算得到的结果是 AB,a1(3) 计算得到的结果是 AB+AB,是我们需要的结果。
Multi-class classification
多分类问题可以将其看做一个一对多方法的拓展。
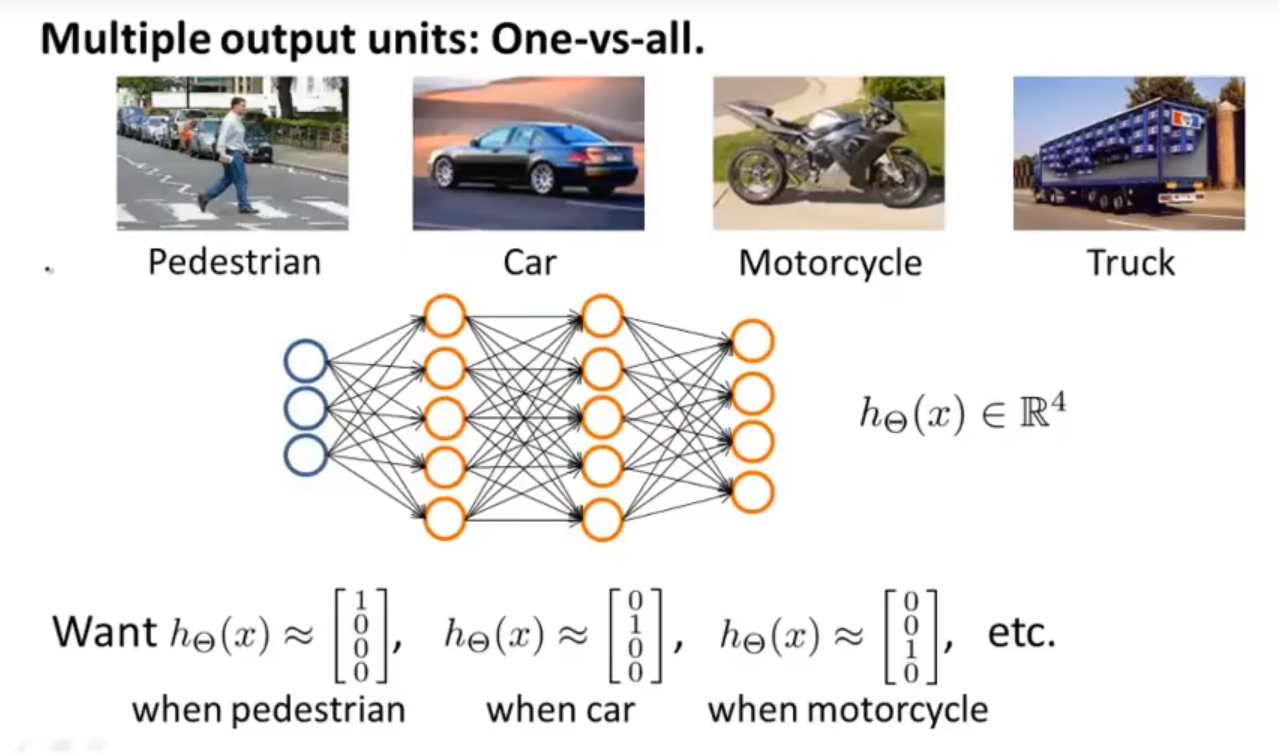
对于上例,我们构造了一个输出层有四个神经元的神经网络,则神经网络的输出将会是一个含有四个数的向量 hΘ(x)∈R4,当数据分别属于不同的类别时,我们希望其能激活不同的输出单元来表示预测的结果,这与逻辑回归中的一对多法非常类似。
此时训练集可表示为 {(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},其中 x(i) 表示一张图片,y(i)∈R4 表示一个四维向量,用来表示每张图片所属的类别。
Cost function
下面用 L 表示神经网络中的总层数,sl 表示第 l 层中不包括偏置单元的单元个数。
- 对于一个二分类问题,输出单元只有一个,输出结果 hΘ(x)∈R,sL=1,为了方便,也可以令 K 为输出层的单元数目,在此类问题中,K=1。
- 对于一个多分类问题,假设需要分为 K 类,则输出单元有 K 个,输出结果 hΘ(x)∈RK,sL=K,注意,一般而言 K≥3,由于一个二分类问题使用一个输出单元即可,而不使用 R2 的向量表示。
在逻辑回归中,我们使用的代价函数为
J(θ)=−m1[i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
在神经网络中,代价函数基本一致,不同的是由于参数不再是一个向量,而是一个矩阵,于是代价函数会有所变动。
具体地,假设 hΘ(x)∈RK,(hΘ(x))i 表示神经网络中输出向量的第 i 个输出,即向量中的第 i 项,则代价函数表示为
J(Θ)=−m1[i=1∑mk=1∑Kyk(i)log(hΘ(x(i))k)+(1−yk(i))log(1−(hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2
对于此函数,直观的理解是将其与逻辑回归的代价函数做对比,由于神经网络中输出是一个 RK 的向量,于是必须存在一个求和将这些输出单元的代价加起来,这就有了内层的求和号;
对于第 k 个输出单元,它预测的类别是 hΘ(x(i))k,实际的类别是 (y(i))k,将其在逻辑回归的代价函数中做替换即可得到神经网络代价函数中的前一项;
而后一项明显为 L2 正则项,逻辑回归中是将除 θ0 以外的所有参数平方后求和,类比到神经网络中,以 a1(i+1) 举例,它会和 a1(i),a2i,…,asi(i) 这 si 个神经元相连,相连时的参数分别为 Θ11(i),Θ12(i),…,Θ1si(i),那么这个神经元表示的逻辑回归即为
a1(i+1)=j=0∑siΘ1j(i)aj(i)
那么这一个逻辑回归对应的 L2 正则项为
j=1∑si(Θ1j(i))2
将第 i+1 层的 si+1 个神经元都考虑进来得到
j=1∑sik=1∑si+1(Θkj(i))2
再把第 1 层到第 L−1 层考虑进来便得到神经网络代价函数中的后一项。
Backpropagation algorithm
反向传播算法是一个让代价函数最小化的算法。在上一节中,我们得到了神经网络的代价函数 J(Θ),本节我们要做的是
Θargmin J(Θ)
为了使用梯度下降法来找到这个最小值,我们需要计算 J(Θ) 和 ∂Θij(l)∂J(Θ) 的值,从而能够使用梯度下降。
反向传播的微积分原理
先从一个最简单的神经网络看起:每一层只有一个神经元,假设这个神经网络有四层,那么就会有三个权重 ω1,ω2,ω3 和三个偏置值 b1,b2,b3。
先考虑最后两个神经元 a(L) 和 a(L−1),且给定一个训练样本,目标值为 y,那么这个神经网络对于该样本的代价为 C0=21(a(L)−y)2。
考虑最后一层的激活值是如何计算的:
a(L)=g(ω(L)a(L−1)+b(L))
其中 g(x) 为 Sigmoid 函数。不妨给 ω(L)a(L−1)+b(L) 取一别名 z(L),于是原式成为
a(L)=g(z(L))
这个过程如下图所示:
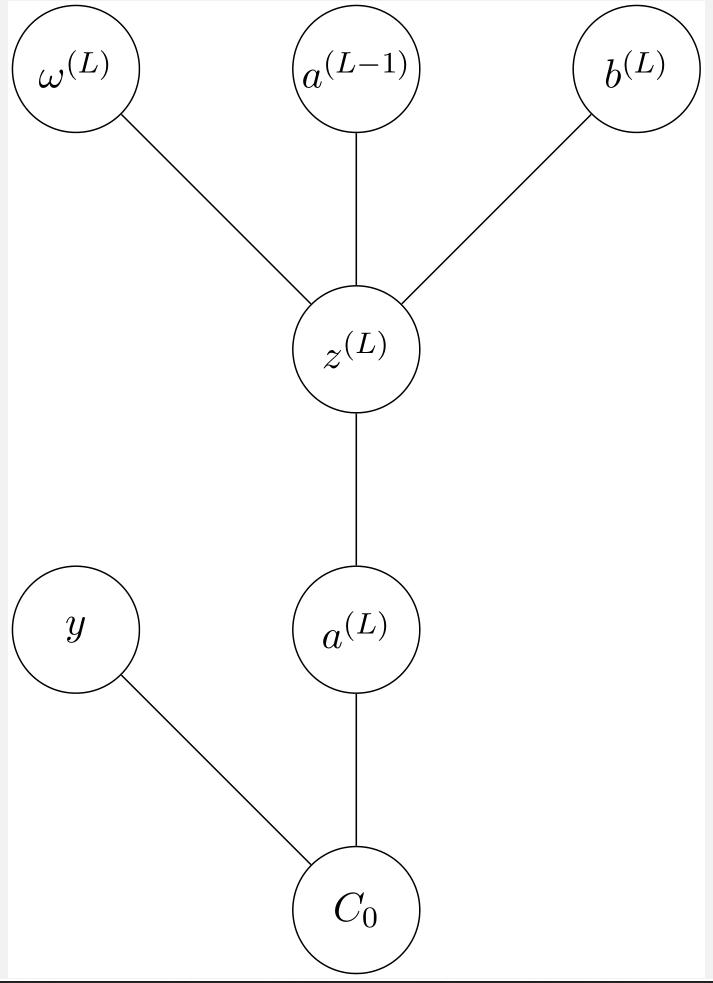
当然,a(L−1) 是根据上一层的权重和偏置值得到的,此处不再画出。
现在,我们考虑计算当 ω(L) 变化时,代价函数的变化程度,即
∂ω(L)∂C0
由于 ω(L) 会首先导致 z(L) 的变化,再导致 a(L) 的变化,我们把上式拆开,根据求导的链式法则得到
∂ω(L)∂C0=∂ω(L)∂z(L)⋅∂z(L)∂a(L)⋅∂a(L)∂C0
下面计算右侧各式的值:
∂a(L)∂C0∂z(L)∂a(L)∂ω(L)∂z(L)=∂a(L)∂21(a(L)−y)2=(a(L)−y)=∂z(L)∂g(z(L))=∂z(L)∂z(L)⋅g′(z(L))=g′(z(L))=∂ω(L)∂(ω(L)a(L−1)+b(L))=a(L−1)
于是
∂ω(L)∂C0=a(L−1)g′(z(L))(a(L)−y)
总的代价函数为许多训练样本所有代价的平均,则有
∂ω(L)∂C=n1k=0∑n−1∂ω(L)∂Ck
而这只是梯度向量
∇C=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡∂ω(1)∂C∂b(1)∂C⋮∂ω(L)∂C∂b(L)∂C⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
的其中一个分量,我们还需要求出代价函数对于偏置值的偏导数,而这只需要将上式中的 ∂ω(L)∂z(L) 改为 ∂b(L)∂z(L) 即可,显然此值为 1,于是
∂b(L)∂C0=1g′(z(L))(a(L)−y)
我们再来看代价函数对上一层的激活值的敏感度
∂a(L−1)∂C0=ω(L)g′(z(L))(a(L)−y)
虽然我们不能直接修改权重,但我们可以通过此来判断代价函数对之前的权重和偏置值的敏感度。
现在来考虑多个神经元的情况。我们令 j 表示最后一层的第 j 个神经元,k 表示倒数第二层的第 k 个神经元,此时最后一层的代价为
C0=21j=0∑sL−1(aj(L)−yj)2
再次提醒,ωjk(L) 表示 L−1 层的第 k 个神经元连向 L 层的第 j 个神经元的权重,与单神经元类似地,令
zj(L)=k=0∑sL−1−1ωjk(L)ak(L−1)+bj(L)
则最后一层的激活值为
aj(L)=g(zj(L))
其中 g(x) 为 Sigmoid 函数。再次利用求导的链式法则,我们得到
∂ω(L)∂C0∂b(L)∂C0∂ak(L−1)∂C0=k=0∑sL−1−1ak(L−1)g′(z(L))(a(L)−y)=1g′(z(L))(a(L)−y)=j=0∑sL−1ωjk(L)g′(z(L))(a(L)−y)
于是我们得到了梯度矩阵 ∇C,根据此我们便可以进行梯度下降。
具体过程
{z(l)=ω(l)a(l−1)+b(l)a(l)=g(z(l))
- 计算输出层误差的方程,按定义有
δj(L)=∂zj(L)∂C
由求导的链式法则得到δj(L)=∂aj(L)∂Cg′(zj(L))(BP1)
写作矩阵形式为δ(L)=∇aC⊙g′(z(L))
若 C 为均方误差,则δ(L)=(a(L)−y)⊙g′(z(L))
其中 ⊙ 表示按元素的乘积,有时也被称为 Hadamard 乘积或 Schur 乘积。举例:
[12]⊙[34]=[1∗32∗4]=[38]
- 再通过下一层的误差 δ(l+1) 表示当前层的误差 δ(l)
δ(l)=((ω(l+1))Tδ(l+1))⊙g′(z(l))(BP2)
- 通过梯度下降更新权重 ω 和偏置值 b
⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧ωjk(l):=ωjk(l)−∂ωjk(l)∂Cbj(l):=bj(l)−∂bj(l)∂C
即
⎩⎪⎪⎨⎪⎪⎧ωjk(l):=ωjk(l)−ak(l−1)δj(l)bj(l):=bj(l)−δj(l)
下面给出 (BP2) 的证明:
δ(l)=∂z(l)∂C=∂z(l+1)∂C⋅∂a(l)∂z(l+1)⋅∂z(l)∂a(l)=(δ(l+1)⋅ω(l+1))⊙g′(z(l))
由于 ω(l+1) 维数为 sl×sl+1,故上式也可以写作
δ(l)=((ωl+1)Tδ(l+1))⊙g′(z(l))
(BP2) 得证。
Gradient checking
梯度检查是一个用来保证每次的前向传播、反向传播都是正确的算法。
当 θ∈R 时,由于导数是图像上某一点处的斜率,我们通过取两点 J(θ+ϵ) 和 J(θ−ϵ),计算这两点连线的斜率 l,当 ϵ 很小时,l 应当与导数相等,即
dθdJ(θ)=ϵ→0lim2ϵJ(θ+ϵ)−J(θ−ϵ)
一般 ϵ 取 10−4 即可。
更普遍地,当 θ∈Rn 时,此时 θ=[θ1,θ2,…,θn],我们只需要对向量中每一个参数的偏导数都进行估计即可。具体地,
∂θi∂J(θ)=ϵ→0lim2ϵJ(…,θi−1,θi+ϵ,θi+1,…)−J(…,θi−1,θi−ϵ,θi+1,…)
在 Matlab 中可以按如下方法进行计算:
1
2
3
4
5
6
7
8
| for i = 1:n,
thetaPlus = theta;
thetaPlus(i) = thetaPlus(i) + EPSILON;
thetaMinus = theta;
thetaMinus(i) = thetaMinus(i) - EPSILON;
gradApprox(i) = (J(thetaPlus) - J(thetaMinus)) / (2 * EPSILON);
end;
|
在正式训练中不要使用梯度检查,因为计算代价相比于反向传播而言非常大。
Random initialization
在梯度下降时,对于参数 Θ,我们需要给定其初值才能运行。
我们应当怎样对 Θ 设定初值呢?
一种可行的想法是,令
1
| initialTheta = zeros(n, 1)
|
这在逻辑回归中是有效的,但这在神经网络中起不到任何作用。
这会表示所有神经元向下一层神经元的贡献全都为 0,下一层神经元的激活项全都相等,这会导致所有的 δ 值全都相等,所有的偏导数也全都相等。在每次梯度下降后, Θ 将会被更新为不为零但所有元素都相等的一个矩阵。
为了避免这种对称的情况,在神经网络中,对参数进行初始化时,我们需要使用随机初始化的思想。
具体地,令每个 Θij(l) 等于 [−ϵ,ϵ] 内的一个随机数,即
−ϵ≤Θij(l)≤ϵ
Matlab 举例:
1
2
| Theta1 = rand(10, 11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta2 = rand(1, 11) * (2 * INIT_EPSILON) - INIT_EPSILON;
|
上面的 rand(x, y) 函数表示生成一个 x×y 的矩阵,其中的值都是 [0,1] 内的随机实数值。
Summarize
- 选择一个合适的神经网络架构:
- 输入层单元个数为特征向量的维度;
- 输出层单元个数为所要区分的类别个数。注意,每个数据的类别应当是一个向量,而不是一个实数。
- 一般来说,默认只用一个隐藏层,如果使用多个隐藏层的话,默认每个隐藏层都具有相同数量的神经元。
- 训练神经网络:
- 随机地初始化权重矩阵;
- 对于每个训练数据 x(i),执行前向传播以得到输出 hΘ(x(i));
- 计算代价函数 J(Θ);
- 执行反向传播计算所有的偏导数 ∂Θjk(l)∂J(Θ);
- 使用一次梯度检查来保证计算结果的正确性,然后禁用梯度检查;
- 通过梯度下降或其他方法求出 Θargmin J(Θ)。