Regularization
The problem of overfitting
过拟合(overfitting)指的是当有多个特征时,预测函数的代价可能会很低,但对于新的预测数据全都错误的情况,这会导致模型的泛化能力较差。

左侧的称为欠拟合(underfitting),右侧的称为过拟合。
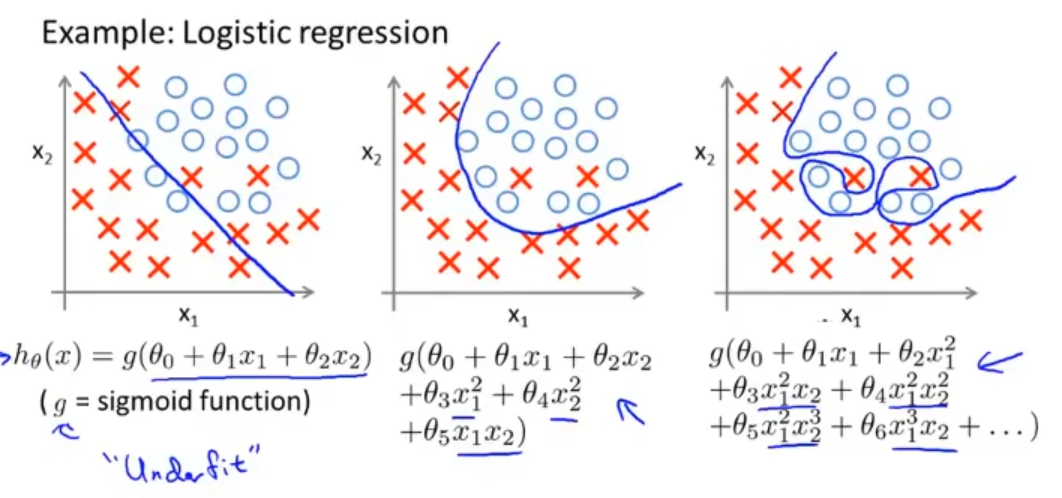
当特征过多而数据过少时,就有可能出现过拟合的情况。
当过拟合的情况发生时,该如何解决呢?
- 减少特征的数量,我们可以选择重要的特征进行保留,也可以使用模型选择算法,这种算法可以自动选择保留哪些特征和选择哪些特征,但是删去某些特征会导致一些信息的丢失,有可能这些信息都是我们需要的;
- 保留所有的特征,进行正则化。我们通过正则化将参数 θj 的量级或数量减小,这在我们有很多特征的时候非常有效,由于每个特征都会对结果产生贡献,所以这种方法是行之有效的。
Cost Function
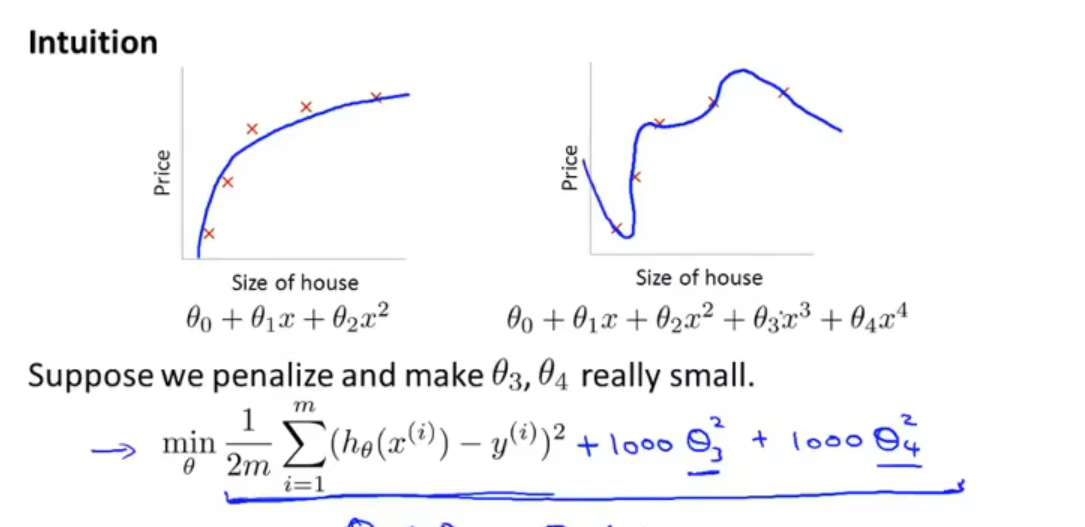
假设此时我们的模型为 θ0+θ1x+θ2x2+θ3x3+θ4x4,我们考虑加入惩罚项,使得 θ3 和 θ4 非常小,即
θargmin2m1i=1∑m(hθ(x(i))−y(i))2+1000θ32+1000θ42
如此,要使上式最小,必须令 θ3 和 θ4 尽量趋近于零,相当于我们尽量去除了 θ3x3 和 θ4x4 两项,最后我们得到的仍是一个拟合效果很好的近似于二次函数的模型。
当参数 θ0,θ1,…,θn 较小时,我们可以得到一个“简化”的模型,过拟合的可能性也会降低。
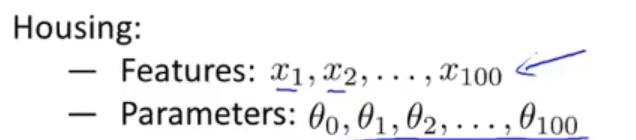
当我们想把 θ0,θ1,…,θ100 每个参数的值都缩小时,可以令代价函数为
J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2]
通过加入第二项,我们可以将所有的参数都缩小。注意,此处是从 1 到 n 进行求和,而不是从 0 到 n,这是一种约定俗成的做法。λj=1∑nθj2 被称为正则化项,λ 被称为正则化参数。这种正则化方法被称为岭回归,正则化项叫做 L2 正则项。
通过正则化可以提高模型的泛化能力。
当最小化 J(θ) 时,我们一方面可以令均方误差最小,从而达到让模型更好地拟合数据,另一方面可以令正则化项尽可能小,从而使得每个参数更小,而二者之间的平衡关系由正则化参数 λ 掌握,使得更好地去拟合训练集的目标和将参数控制的更小的目标同时实现,从而使得模型尽可能简单,避免出现过拟合的情况。
通过正则化,我们可以得到一个更加光滑、简单的曲线,同时能拟合所有的数据,也即得到了一个更好的假设模型。
如果正则化参数过大,惩罚的程度过高,我们会得到一个除了 θ0 以外,其他的参数都趋于零的结果,相当于把假设函数的全部项都忽略掉了,这就导致了欠拟合的现象。

Regularized linear regression
- 梯度下降法:我们将线性回归中的梯度下降式进行处理,分成 θ0 和 θ1,…,θn 两类,即:
θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))x0(i)
θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i) (j=1,2,3,…,n)
由于正则化中正则化式是从 1 到 n 进行求和的,所以我们如此分类也是符合直觉的。
加入正则化式后,j=1,2,…,n 的梯度下降式应当改变,即加上正则化式对 θj 的偏导,修改后得到
θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))x0(i)
θj:=θj−α[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj] (j=1,2,3,…,n)
化简 j=1,2,…,n 的梯度下降式后得到
θj:=θj(1−αmλ)−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
- 规范方程法:构造矩阵 X 为一个 m×(n+1) 的矩阵
X=⎣⎢⎢⎢⎡(x(1))T⋮(x(m))T⎦⎥⎥⎥⎤
y 为一个 Rm 维的向量
y=⎣⎢⎢⎡y(1)⋮y(m)⎦⎥⎥⎤
为了最小化代价函数 J(θ),我们知道其解为 θ=(XTX)−1XTy,但此时由于加入了正则项,需要加上正则项对 θj 的偏导等于 0 时的解,结果为
θ=⎝⎜⎜⎜⎜⎜⎜⎜⎛XTX+λ⎣⎢⎢⎢⎢⎢⎢⎢⎡0111⋱1⎦⎥⎥⎥⎥⎥⎥⎥⎤⎠⎟⎟⎟⎟⎟⎟⎟⎞−1XTy
矩阵为一个主对角线上除了第一行第一列元素为 0,其他全为 1 的 (n+1)×(n+1) 的矩阵。
Regularized logistic regression
对于逻辑回归,我们同样使用岭回归,通过对代价函数添加 L2 正则项进行正则化:
J(θ)=−m1i=1∑m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
通过如此,可以惩罚参数 θ1,θ2,…,θn,使它们在尽可能地小的同时尽可能好地完成任务。
逻辑回归的梯度下降式为:
θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))x0(i)
θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i), (j=1,2,3,…,n)
在加上 L2 正则项后,第一个式子不变,第二个式子变为
θj:=θj−α[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj], (j=1,2,3,…,n)
化简后得
θj:=(1−mλ)θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i), (j=1,2,3,…,n)