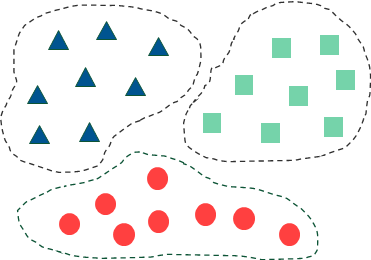
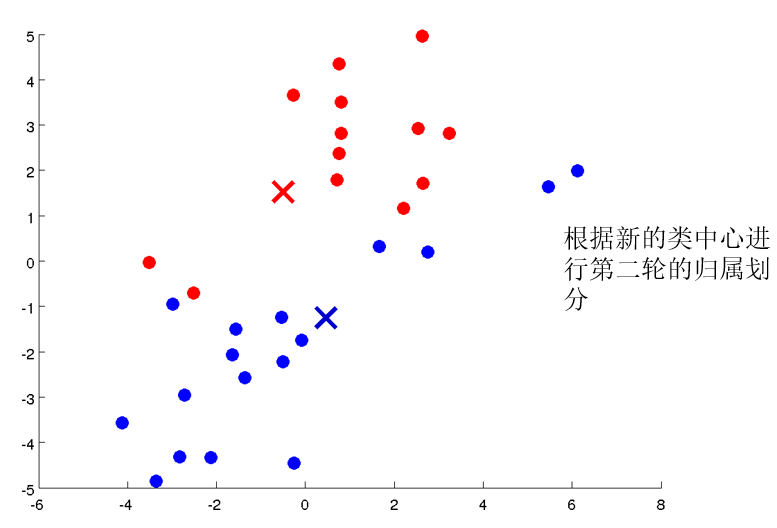
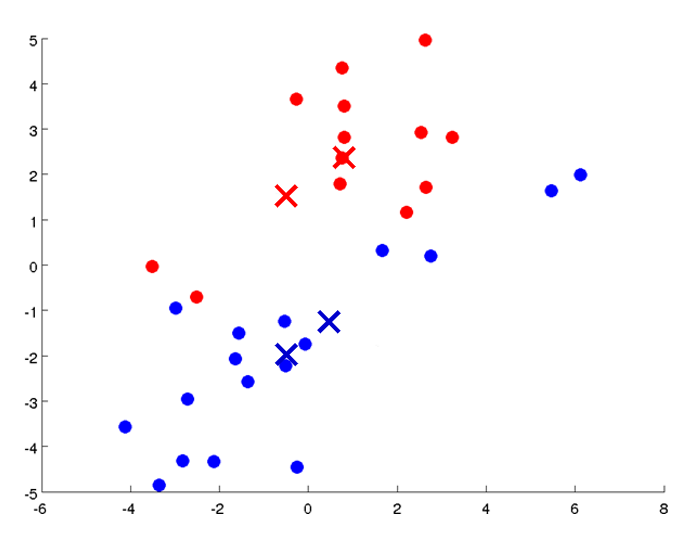
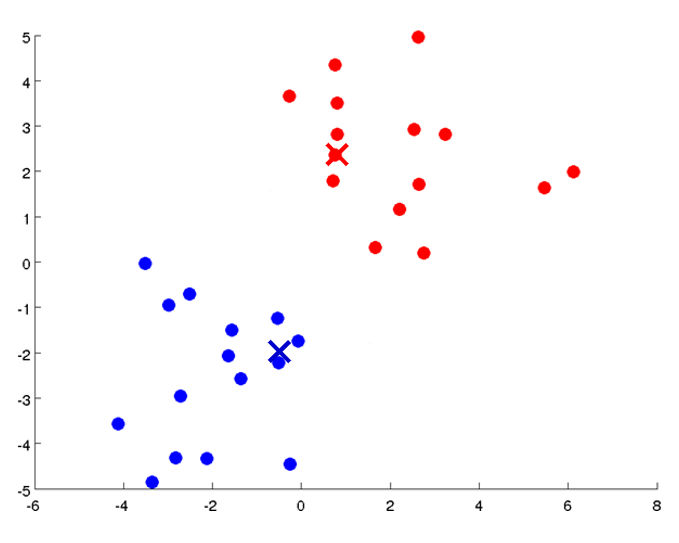
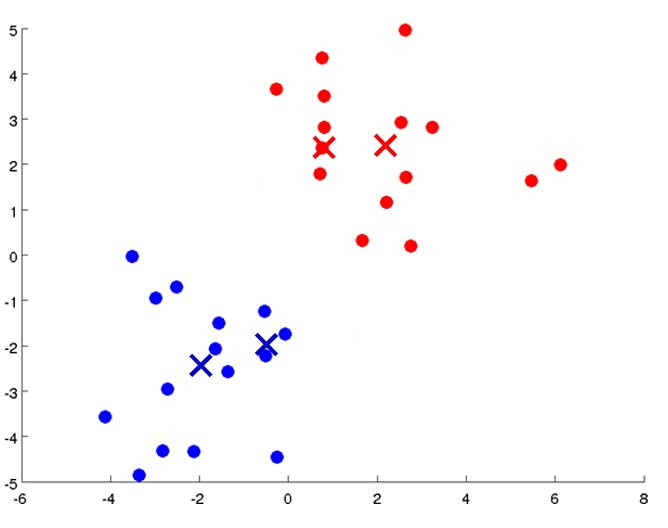
在无监督学习中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。此类学习任务中研究最多、应用最广的是“聚类”(clustering)。
常见的无监督学习任务还有密度估计、异常检测等。
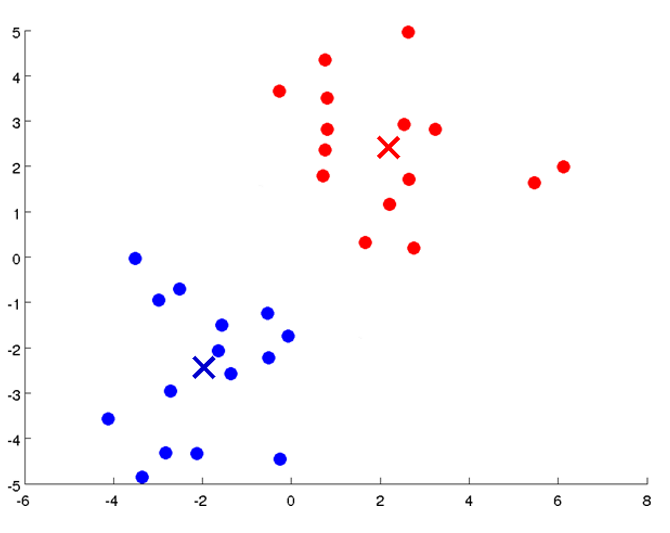
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称作一个“簇”。
形式化地,假定样本集 D = { x 1 , x 2 , … , x m } D = \left\{\boldsymbol{x}_1,\boldsymbol{x}_2, \dots,\boldsymbol{x}_m\right\} D = { x 1 , x 2 , … , x m } m m m x i = ( x i 1 ; x i 2 ; … ; x i n ) \boldsymbol{x}_i = \left(x_{i1};x_{i2};\dots;x_{in}\right) x i = ( x i 1 ; x i 2 ; … ; x i n ) n n n D D D { C l ∣ l = 1 , 2 , … , k } \left\{C_l \mid l = 1, 2, \dots, k\right\} { C l ∣ l = 1 , 2 , … , k } C l ′ ⋂ l ′ ≠ l C l = ∅ C_{l'} \bigcap_{l' \neq l} C_l = \varnothing C l ′ ⋂ l ′ = l C l = ∅ D = ⋃ l = 1 k C l D = \bigcup_{l=1}^{k}{C_l} D = ⋃ l = 1 k C l
令 λ j ∈ { 1 , 2 , … , k } \lambda_j \in \left\{1, 2,\dots, k\right\} λ j ∈ { 1 , 2 , … , k } x j \mathbf{x}_j x j x j ∈ λ j \mathbf{x}_j \in \lambda_j x j ∈ λ j m m m λ ⃗ = ( λ 1 ; λ 2 ; … ; λ k ) \vec\lambda = \left(\lambda_1; \lambda_2;\dots;\lambda_k\right) λ = ( λ 1 ; λ 2 ; … ; λ k )
对于聚类的结果,我们希望“簇内相似度”高,而“簇间相似度”低。下面是一些常用的聚类性能度量的内部指标:
DBI = 1 k ∑ i = 1 k max j ≠ i ( avg ( C i ) + avg ( C j ) d cen ( μ i , μ j ) ) \operatorname{DBI} = \dfrac 1k \sum\limits_{i=1}^k{\max_{j \neq i}\left(\dfrac{\operatorname{avg}(C_i) + \operatorname{avg}(C_j)}{d_{\text{cen}}(\mu_i, \mu_j)}\right)}
D B I = k 1 i = 1 ∑ k j = i max ( d cen ( μ i , μ j ) a v g ( C i ) + a v g ( C j ) )
DI = min 1 ≤ i ≤ k { min j ≠ i ( d min ( C i , C j ) max 1 ≤ l ≤ k diam ( C l ) ) } \operatorname{DI} = \min_{1 \leq i \leq k}\left\{\min_{j \neq i}\left(\dfrac{d_{\min}(C_i, C_j)}{\max\limits_{1 \leq l \leq k}\operatorname{diam}(C_l)}\right)\right\}
D I = 1 ≤ i ≤ k min ⎩ ⎪ ⎨ ⎪ ⎧ j = i min ⎝ ⎛ 1 ≤ l ≤ k max d i a m ( C l ) d m i n ( C i , C j ) ⎠ ⎞ ⎭ ⎪ ⎬ ⎪ ⎫
其中,avg ( C ) \operatorname{avg}(C) a v g ( C ) C C C diam ( C ) \operatorname{diam}(C) d i a m ( C ) C C C d min ( C i , C j ) d_{\min}(C_i, C_j) d m i n ( C i , C j ) C i C_i C i C j C_j C j d cen ( C i , C j ) d_{\text{cen}}(C_i, C_j) d cen ( C i , C j ) C i C_i C i C j C_j C j μ i \mu_i μ i C C C
μ = 1 ∣ C ∣ ∑ 1 ≤ i ≤ ∣ C ∣ x i avg ( C ) = 2 ∣ C ∣ ( ∣ C ∣ − 1 ) ∑ 1 ≤ i < j ≤ ∣ C ∣ dist ( x i , x j ) diam ( C ) = max 1 ≤ i < j ≤ ∣ C ∣ dist ( x i , x j ) d min ( C i , C j ) = min x i ∈ C i , x j ∈ C j dist ( x i , x j ) d cen ( C i , C j ) = dist ( μ i , μ j ) \begin{aligned}
\mu &= \dfrac 1{|C|}\sum\limits_{1 \leq i \leq |C|} \boldsymbol{x}_i \\
\operatorname{avg}(C) &= \dfrac{2}{|C|(|C|-1)} \sum\limits_{1 \leq i < j \leq |C|} \operatorname{dist}(\boldsymbol{x}_i, \boldsymbol{x}_j) \\
\operatorname{diam}(C) &= \max_{1 \leq i < j \leq |C|} \operatorname{dist}(\boldsymbol{x}_i, \boldsymbol{x}_j) \\
d_{\min}(C_i, C_j) &= \min_{\boldsymbol{x}_i \in C_i, \boldsymbol{x}_j \in C_j} \operatorname{dist}(\boldsymbol{x}_i, \boldsymbol{x}_j) \\
d_{\text{cen}}(C_i, C_j) &= \operatorname{dist}(\mu_i, \mu_j)
\end{aligned}
μ a v g ( C ) d i a m ( C ) d m i n ( C i , C j ) d cen ( C i , C j ) = ∣ C ∣ 1 1 ≤ i ≤ ∣ C ∣ ∑ x i = ∣ C ∣ ( ∣ C ∣ − 1 ) 2 1 ≤ i < j ≤ ∣ C ∣ ∑ d i s t ( x i , x j ) = 1 ≤ i < j ≤ ∣ C ∣ max d i s t ( x i , x j ) = x i ∈ C i , x j ∈ C j min d i s t ( x i , x j ) = d i s t ( μ i , μ j )
从上述公式中我们可以发现,寻找一个计算距离的函数 dist ( ⋅ , ⋅ ) \operatorname{dist}(\cdot, \cdot) d i s t ( ⋅ , ⋅ )
给定样本 x i = ( x i 1 ; x i 2 ; … ; x i n ) \boldsymbol{x}_i = \left(x_{i1};x_{i2};\dots;x_{in}\right) x i = ( x i 1 ; x i 2 ; … ; x i n ) x j = ( x j 1 ; x j 2 ; … ; x j n ) \boldsymbol{x}_j = \left(x_{j1};x_{j2};\dots;x_{jn}\right) x j = ( x j 1 ; x j 2 ; … ; x j n )
dist mk ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ p ) 1 p \operatorname{dist}_{\text{mk}}(\boldsymbol{x}_i, \boldsymbol{x}_j) = \left(\sum\limits_{u = 1}^n{|x_{iu} - x_{ju}|^p}\right)^{\frac 1p}
d i s t mk ( x i , x j ) = ( u = 1 ∑ n ∣ x i u − x j u ∣ p ) p 1
同时,上式即为 x i − x j \boldsymbol{x}_i - \boldsymbol{x}_j x i − x j L p \boldsymbol{L}_p L p ∣ ∣ x i − x j ∣ ∣ p ||\boldsymbol{x}_i - \boldsymbol{x}_j||_p ∣ ∣ x i − x j ∣ ∣ p
当 p = 1 p = 1 p = 1
dist man ( x i , x j ) = ∥ x i − x j ∥ 1 = ∑ u = 1 n ∣ x i u − x j u ∣ \operatorname{dist}_{\text {man }}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\left\|\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right\|_{1}=\sum_{u=1}^{n}\left|x_{i u}-x_{j u}\right|
d i s t man ( x i , x j ) = ∥ x i − x j ∥ 1 = u = 1 ∑ n ∣ x i u − x j u ∣
当 p = 2 p = 2 p = 2
dist e d ( x i , x j ) = ∥ x i − x j ∥ 2 = ∑ u = 1 n ∣ x i u − x j u ∣ 2 \operatorname{dist}_{\mathrm{ed}}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\left\|\boldsymbol{x}_{i}-\boldsymbol{x}_{j}\right\|_{2}=\sqrt{\sum_{u=1}^{n}\left|x_{i u}-x_{j u}\right|^{2}}
d i s t e d ( x i , x j ) = ∥ x i − x j ∥ 2 = u = 1 ∑ n ∣ x i u − x j u ∣ 2
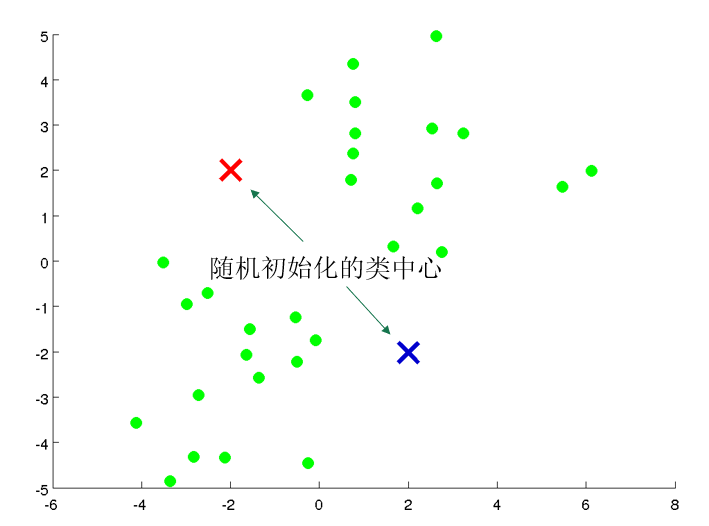
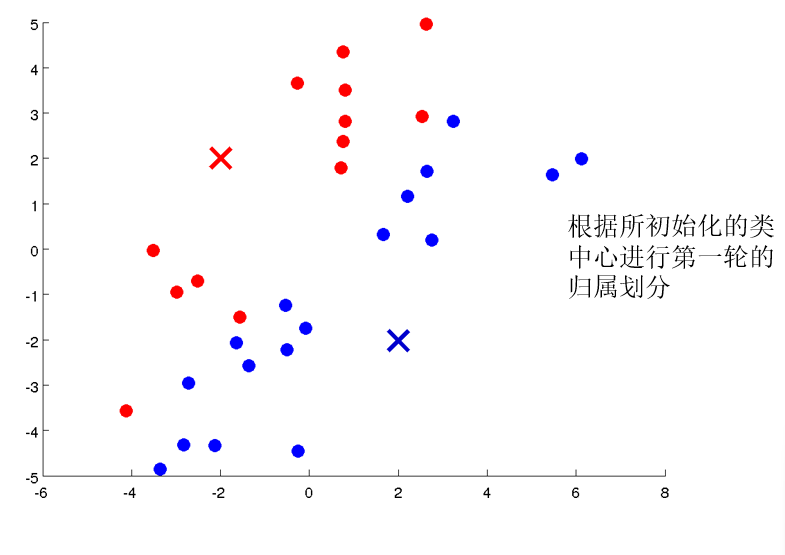
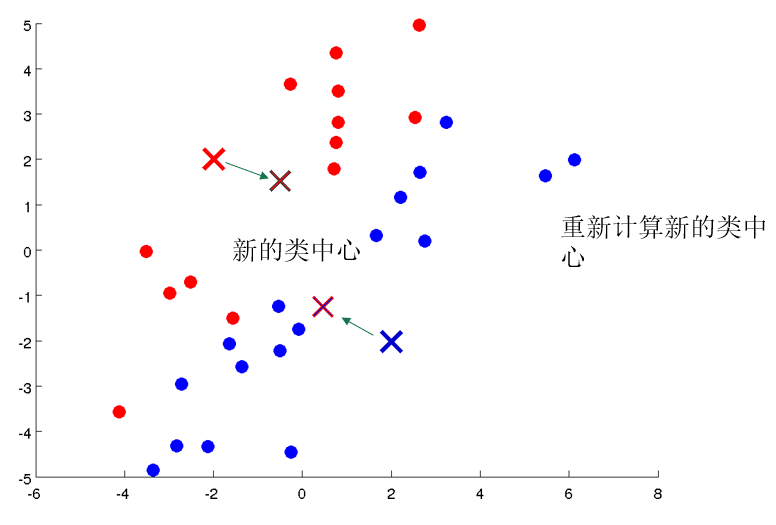
原型聚类亦称为“基于原型的聚类”,此类算法假设聚类结构能通过一组原型刻画,在现实聚类任务中极为常用。通常情况下,算法先对原型进行初始化,再对原型进行迭代更新求解。
给定样本集 D = { x 1 , x 2 , … , x m } D = \left\{\boldsymbol{x}_1, \boldsymbol{x}_2, \dots, \boldsymbol{x}_m\right\} D = { x 1 , x 2 , … , x m } C = { C 1 , C 2 , … , C k } \mathcal{C} = \left\{C_1, C_2, \dots, C_k\right\} C = { C 1 , C 2 , … , C k }
E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 2 E = \sum\limits_{i=1}^k{\sum\limits_{\boldsymbol{x} \in C_i} ||\boldsymbol{x} - \mu_i||_2^2}
E = i = 1 ∑ k x ∈ C i ∑ ∣ ∣ x − μ i ∣ ∣ 2 2
其中 μ i = 1 ∣ C i ∣ ∑ x ∈ C i x \mu_i = \frac 1{|C_i|}\sum_{\boldsymbol{x} \in C_i} \boldsymbol{x} μ i = ∣ C i ∣ 1 ∑ x ∈ C i x C i C_i C i E E E E E E
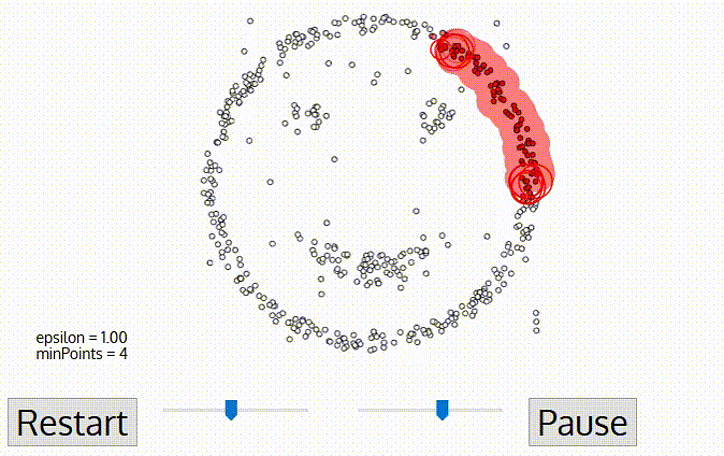
密度聚类也称为“基于密度的聚类”。此类算法假设聚类结构能通过样本分布的紧密程度来确定。通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇来获得最终的聚类结果。
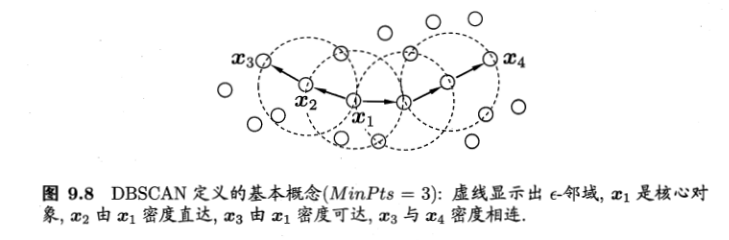
DBSCAN 算法是一种著名的密度聚类算法,它基于一组“邻域”参数 ( ϵ , M i n P t s ) (\epsilon, MinPts) ( ϵ , M i n P t s )
给定数据集 D = { x 1 , x 2 , … , x m } D = \left\{\boldsymbol{x}_1, \boldsymbol{x}_2, \dots, \boldsymbol{x}_m\right\} D = { x 1 , x 2 , … , x m }
ϵ \epsilon ϵ x j ∈ D \boldsymbol{x}_j \in D x j ∈ D ϵ \epsilon ϵ D D D x j \boldsymbol{x}_j x j ϵ \epsilon ϵ N ϵ ( x j ) = { x i ∈ D ∣ dist ( x i , x j ) ⩽ ϵ } N_{\epsilon}\left(\boldsymbol{x}_{j}\right)=\left\{\boldsymbol{x}_{i} \in D \mid \operatorname{dist}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right) \leqslant \epsilon\right\} N ϵ ( x j ) = { x i ∈ D ∣ d i s t ( x i , x j ) ⩽ ϵ } 核心对象:若 x j \boldsymbol{x}_j x j ϵ \epsilon ϵ M i n P t s MinPts M i n P t s ∣ N ϵ ( x j ) ∣ ≥ M i n P t s \left|N_\epsilon(\boldsymbol{x}_j)\right| \geq MinPts ∣ N ϵ ( x j ) ∣ ≥ M i n P t s x j \boldsymbol{x}_j x j
密度直达:若 x j \boldsymbol{x}_j x j x i \boldsymbol{x}_i x i ϵ \epsilon ϵ x i \boldsymbol{x}_i x i x j \boldsymbol{x}_j x j x i \boldsymbol{x}_i x i
密度可达:对 x i \boldsymbol{x}_i x i x j \boldsymbol{x}_j x j p 1 , p 2 , … , p n \boldsymbol{p}_1, \boldsymbol{p}_2, \dots, \boldsymbol{p}_n p 1 , p 2 , … , p n p 1 = x i \boldsymbol{p}_1 = \boldsymbol{x}_i p 1 = x i p n = x j \boldsymbol{p}_n = \boldsymbol{x}_j p n = x j p i + 1 \boldsymbol{p}_{i+1} p i + 1 p i \boldsymbol{p}_i p i x j \boldsymbol{x}_j x j x i \boldsymbol{x}_i x i
密度相连:对 x i \boldsymbol{x}_i x i x j \boldsymbol{x}_j x j x k \boldsymbol{x}_k x k x i \boldsymbol{x}_i x i x j \boldsymbol{x}_j x j x k \boldsymbol{x}_k x k x i \boldsymbol{x}_i x i x j \boldsymbol{x}_j x j
DBSCAN 将“簇”定义为:有密度可达关系导出的最大的密度相连样本集合。
形式化地,给定邻域参数 ( ϵ , M i n P t s ) (\epsilon, MinPts) ( ϵ , M i n P t s ) C ⊆ D C \subseteq D C ⊆ D
连接性:x i ∈ C \boldsymbol{x}_i \in C x i ∈ C x j ∈ C ⟹ \boldsymbol{x}_j \in C \Longrightarrow x j ∈ C ⟹ x i \boldsymbol{x}_i x i x j \boldsymbol{x}_j x j
最大性:x i ∈ C \boldsymbol{x}_i \in C x i ∈ C x j \boldsymbol{x}_j x j x i \boldsymbol{x}_i x i ⟹ \Longrightarrow ⟹ x j ∈ C \boldsymbol{x}_j \in C x j ∈ C
实际上,若 x \boldsymbol{x} x x \boldsymbol{x} x X = { x ′ ∈ D ∣ x ′ 由 x 密度可达 } X = \left\{\boldsymbol{x}' \in D \mid \boldsymbol{x}' \text{由}\boldsymbol{x}\text{密度可达}\right\} X = { x ′ ∈ D ∣ x ′ 由 x 密度可达 } X X X
1-7 行中,算法先根据给定的邻域参数找出所有核心对象;10-24 行中,以任一核心对象为出发点,找出由其密度可达的样本生成聚类簇,直到所有核心对象均被访问过为止。
层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集划分既可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。
AGNES 算法是一种采取自底向上聚合策略的层次聚类算法。
首先,将样本中的每一个样本看做一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并,该过程不断重复,直到达到预设的聚类簇的个数。
两个聚类簇 C i C_i C i C j C_j C j
最小距离:d min ( C i , C j ) = min x ∈ C i , z ∈ C j dist ( x , z ) d_{\min}(C_i, C_j) = \min\limits_{\boldsymbol{x} \in C_i, \boldsymbol{z} \in C_j} \operatorname{dist}(\boldsymbol{x}, \boldsymbol{z}) d m i n ( C i , C j ) = x ∈ C i , z ∈ C j min d i s t ( x , z )
最大距离:d max ( C i , C j ) = max x ∈ C i , z ∈ C j dist ( x , z ) d_{\max}(C_i, C_j) = \max\limits_{\boldsymbol{x} \in C_i, \boldsymbol{z} \in C_j} \operatorname{dist}(\boldsymbol{x}, \boldsymbol{z}) d m a x ( C i , C j ) = x ∈ C i , z ∈ C j max d i s t ( x , z )
平均距离:d avg ( C i , C j ) = 1 ∣ C i ∣ ∣ C j ∣ ∑ x ∈ C i ∑ z ∈ C j dist ( x , z ) \displaystyle d_{\text {avg}}\left(C_{i}, C_{j}\right)=\frac{1}{\left|C_{i}\right|\left|C_{j}\right|} \sum_{\boldsymbol{x} \in C_{i}} \sum_{\boldsymbol{z} \in C_{j}} \operatorname{dist}(\boldsymbol{x}, \boldsymbol{z}) d avg ( C i , C j ) = ∣ C i ∣ ∣ C j ∣ 1 x ∈ C i ∑ z ∈ C j ∑ d i s t ( x , z )
当聚类簇距离由 d min d_{\min} d m i n d max d_{\max} d m a x d avg d_{\text{avg}} d avg
1-9 行,算法先对仅含一个样本的初始聚类簇和相应的距离矩阵进行初始化;11-23 行,AGNES 不断合并距离最近的聚类簇,并对合并得到的距离矩阵进行更新;上述过程不断重复,直到达到预设的聚类簇数。
ps: 这个 O ( n 2 ) \mathcal{O}(n^2) O ( n 2 )