支持向量机
支持向量机(support vector machines)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,它在学习复杂的非线性方程时能提供一种更加清晰和强大的方法。
在 Logistic 回归中,如果要令 y=1,则有 hθ(x)=1+e−θTx1≈1,即 θTx≫0;当 y=0 时有 hθ(x)≈0,即 θTx≪0。
对于 Logistic 回归,其代价函数为
−(yloghθ(x)+(1−y)log(1−hθ(x)))
将 hθ(x) 代入上述函数得
−ylog1+e−θTx1−(1−y)log(1−1+e−θTx1)
当 y=1 时,代价函数变为 −log1+e−z1,此时令 z→+∞,代价函数将会趋近于 0,这也是为什么在看见 y=1 这样的样本时,会将 z 赋值为一个极大值;类似地,当看见 y=0 这样的样本时,会将 z 赋值为一个极小值。
在 Logistic 回归中,我们的代价函数 J(θ) 为
J(θ)=θminm1[i=1∑my(i)(−loghθ(x(i)))+(1−y(i))(−log(1−hθ(x(i))))]+2mλj=1∑nθj2
上式中后一项为正则化参数。
在 SVM 中,代价函数为
J(θ)=θmin[Ci=1∑my(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21j=1∑nθj2
其中 cost0,cost1 为合页损失函数。由于 m1 是常数,对 θ 的取值不会造成影响,于是将 m1 约去。在 SVM 中,权重参数将不在正则化项上,而是在前一项,按照惯例设为 C。
SVM 的输出并不是概率,而是预测值,即:
hθ(x)={1,0,if θTx≥0otherwise
Large Margin Intuition

当 C 非常大时,我们希望使第一项的值尽量为 0,则当 y(i)=1 时,我们希望得到 θTx≥1;当 y(i)=0 时,我们希望得到 θTx≤−1,则此时最优化问题变为
θmin21j=1∑nθj2s.t. {θTx(i)≥1,θTx(i)≤−1,if y(i)=1if y(i)=0
通过求解上述的最优化问题,我们可以得到一个更加鲁棒的超平面(决策边界)。
距离超平面最近的几个训练样本点被称为支持向量,两个不同类支持向量到超平面的距离之和被称为间隔(margin)。
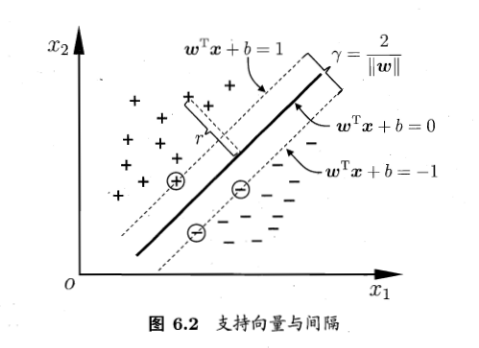
当 C 非常大时,模型会对离群值非常敏感,有可能为了追求正确率而将间隔变小,所以我们需要调整参数 C 以权衡间隔和错误率。
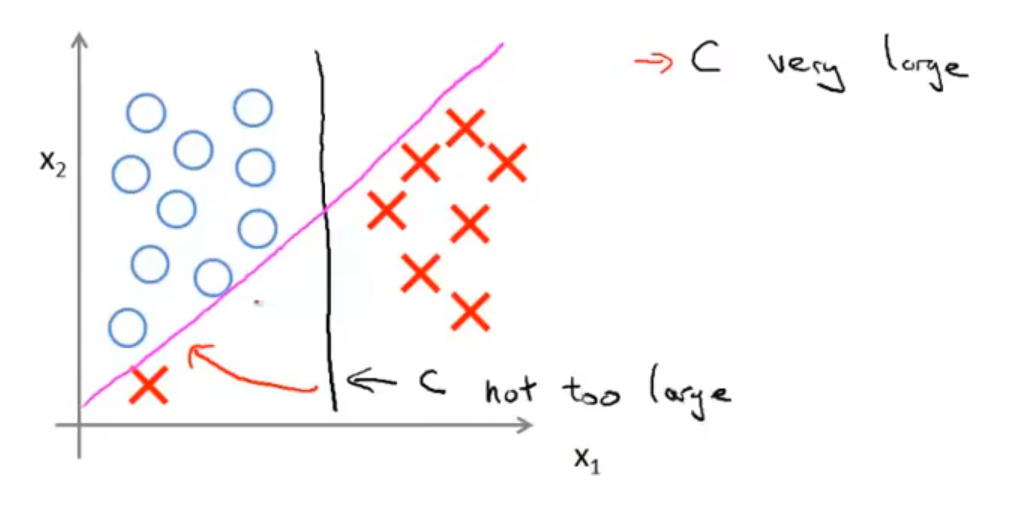
当样本不是线性可分时,也会出现上述情况,我们需要通过核化法将问题升维,以转化为线性可分的问题,或者容忍合适的错误率,以获取鲁棒的超平面。
The mathematics behind large margin classification
首先回顾向量的内积:设 u=[u1u2],v=[v1v2],则 u 和 v 的内积为 uTv=p⋅∥u∥=vTu=u1v1+u2v2,其中 p 是 v 在 u 上的投影,∥u∥ 表示 u 的长度(范数)。
在下面的过程中,我们对要最优化的目标函数做一些简化:令 θ0=0,n=2,目标函数可以写做
===21j=1∑nθj221(θ12+θ22)21(θ12+θ22)221∣∣θ∣∣2
其中,θ=[b1b2]。
观察原最优化问题的限制条件:
{θTx(i)≥1,θTx(i)≤−1,if y(i)=1if y(i)=0
将限制条件和向量内积做对比,可以得到:
{p(i)⋅∣∣θ∣∣≥1,p(i)⋅∣∣θ∣∣≤−1,if y(i)=1if y(i)=0
其中 p(i) 表示 x(i) 在 θ 上的投影。
此时原最优化问题成为:
θmin21∣∣θ∣∣2s.t. {p(i)⋅∣∣θ∣∣≥1,p(i)⋅∣∣θ∣∣≤−1,if y(i)=1if y(i)=0
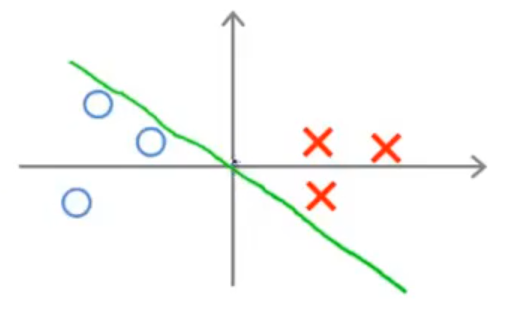
对于上图这个超平面,它并不是最优的,这是因为 θ 是这个超平面的法向量,作出后如下图所示:
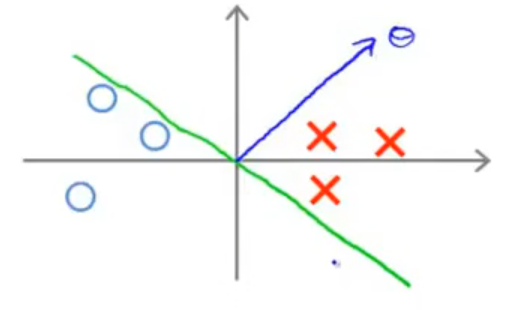
将 p(i) 画出后,可以发现所有的 ∣p(i)∣ 都比较小:
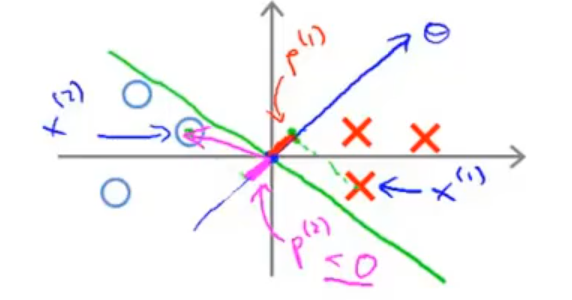
这意味着,如果要满足最优化问题的限制条件,∥θ∥ 需要尽可能地大,这与最优化问题中最优化的表达式相违背!由此可以看出,这不是一个好的超平面。
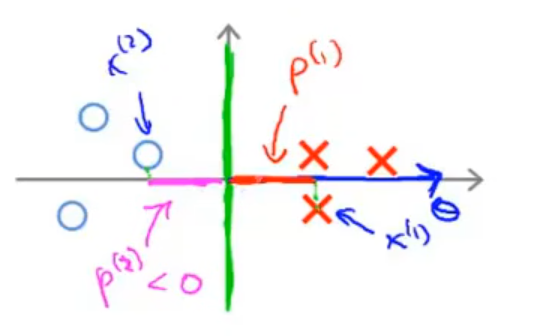
当选择这个超平面时,∣p(i)∣ 会大得多,∥θ∥ 从而会相应的小很多,于是 SVM 会选择这个超平面,而不是上面那一个。
当 θ0=0 时,超平面将不再经过 (0,0) 点,但 SVM 依然会做类似的工作,使得 margin 最大。
Kernels
我们令 fi 表示第 i 个特征变量,则预测函数 hθ(x) 成为
hθ(x)=[θ0+θ1f1+θ2f2+⋯≥0]
其中 [x] 表示如果布尔表达式 x 为真,则取值为 1,反之为 0。
有没有一种较好的方法来合理地选取各个特征变量?下面介绍一种构造方法。
下面例子中,我们只构造三个特征变量 f1,f2,f3,特征为 x1,x2。
我们在 x1,x2 形成的二维空间上选取三个点 l(1),l(2) 和 l(3),则每个特征变量由下式构造得到:
fi=κ(x,l(i))=exp(−2σ2∥x−l(i)∥2)=exp(−2σ2∑j=1n(xj−lj(1))2)
其中,κ(⋅,⋅) 被称为核函数,此处我们使用的是高斯核函数。此处的 σ 与正态分布中的 σ 对图像的影响类似,当 σ 缩小时,图像会更加的陡峭,从最高点处向下时,下降的速度会更快;反之则会更平缓,下降的速度会更慢。我们称 σ 影响着图像的平滑程度。
当 x 和 l(i) 非常接近时,fi≈1,而当二者之间的距离非常远时,fi≈0。
假设我们已经得到参数的值:θ0=−0.5,θ1=1,θ2=1,θ3=0,则靠近 l(1) 和 l(2) 的点将会被预测为 y=1,其余位置将会被预测为 y=0。根据参数,我们可以得到一个超平面,落入这个超平面中的所有数据点都会被预测为 y=1。
具体实践中,我们可以将每个数据 x(i) 在超平面上的位置作为一个标记点 l(i),这样我们可以得到 m 个标记,其中 m 为训练集规模。
此时我们可以得到 m 个特征变量 f1,f2,…,fm。我们将其写作一个向量,同时按照惯例,我们在向量中加入 f0,即
f=⎣⎢⎢⎢⎢⎢⎢⎡f0=1f1f2⋮fm⎦⎥⎥⎥⎥⎥⎥⎤
对于训练集中的一个数据 {x(i),y(i)},我们可以计算得到一个新的特征向量
f(i)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡f0(i)=1f1(i)=κ(x(i),l(1))f2(i)=κ(x(i),l(2))f3(i)=κ(x(i),l(3))⋮fm(i)=κ(x(i),l(m))⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
这样,我们可以把一个 n+1 维的数据 x(i) 转化为一个 m+1 的特征向量 f(i)。此时,预测函数将会变为
hθ(x)=[θTf(i)≥0]
其中,θ∈Rm+1,f(i)∈Rm+1。
最优化问题为:
θargmin Ci=1∑mcost1(θTf(i))+(1−y(i))cost0(θTf(i))+21j=1∑mθj2
当把 θ0 省略后,L2 正则项可以写作 21θTθ。
在上式中,C 的作用与 λ1 基本相当:
- 当 C 较大时,偏差小,方差大,容易过拟合;
- 当 C 较小时,偏差大,方差小,容易欠拟合。
常用的核函数有如下几种:
| 名称 |
表达式 |
参数 |
| 线性核 |
κ(x,l)=xTl |
|
| 多项式核 |
κ(x,l)=(xTl+r)d |
r 为偏移量,d≥1 为多项式次数 |
| 高斯核 |
κ(x,l)=exp(−2σ2∣x−l∣2) |
σ>0 为高斯核的带宽 |
| 拉普拉斯核 |
κ(x,l)=exp(−σ∣x−l∣) |
σ>0 |
| Sigmoid 核 |
κ(x,l)=tanh(βxTl+θ) |
β>0,θ<0 |