卷积神经网络
卷积神经网络
卷积神经网络(CNN)是一个专门用于图像处理的神经网络。
从图像分类说起
下面的讨论都是基于假设所有图像的尺寸是固定的,不会突然出现大小不一致的图片。
图像识别模型的输入是一张图片,输出是一个独热(one-hot)的向量 ,只有模型认为最有可能的类别为 1,其余都为 0。这个向量的长度表示着当前模型能识别出的种类数目。模型在输出独热向量之前,会先通过 Softmax 输出一个向量 ,我们希望 和 的交叉熵尽可能地小。
对于输入,人眼看到的是一张三维的图像,计算机看到的是什么呢?计算机看到的是一个三维的张量(粗略的认为是维度大于 2 的矩阵),一维代表图片的宽,一维代表图片的高,另一维代表这张图片通道的个数,当给定一张彩色图片时,图片通道数为 3,分别表示 R、G 和 B。
当我们把一张图片“拉直”成一个向量之后,就可以放到神经网络中让它进行识别分类了。
目前为止,我们只学到了全连接神经网络,如果输入是一个 的向量,第二层的神经元有 1000 个,那么将会有 个权重,这是一个非常巨大的数,计算过程会非常缓慢,同时过拟合的风险也会增加。
考虑图像识别的特性,我们并不需要每一个神经元和输入的每一维都有一个权重,即全连接是不必要的。
Observation
-
对于每个隐藏层的神经元来说,没有必要去识别整张图片,只需要令每个神经元都识别到一些重要的部分即可,而这其中重要的部分一定是比整张图片要小得多的;
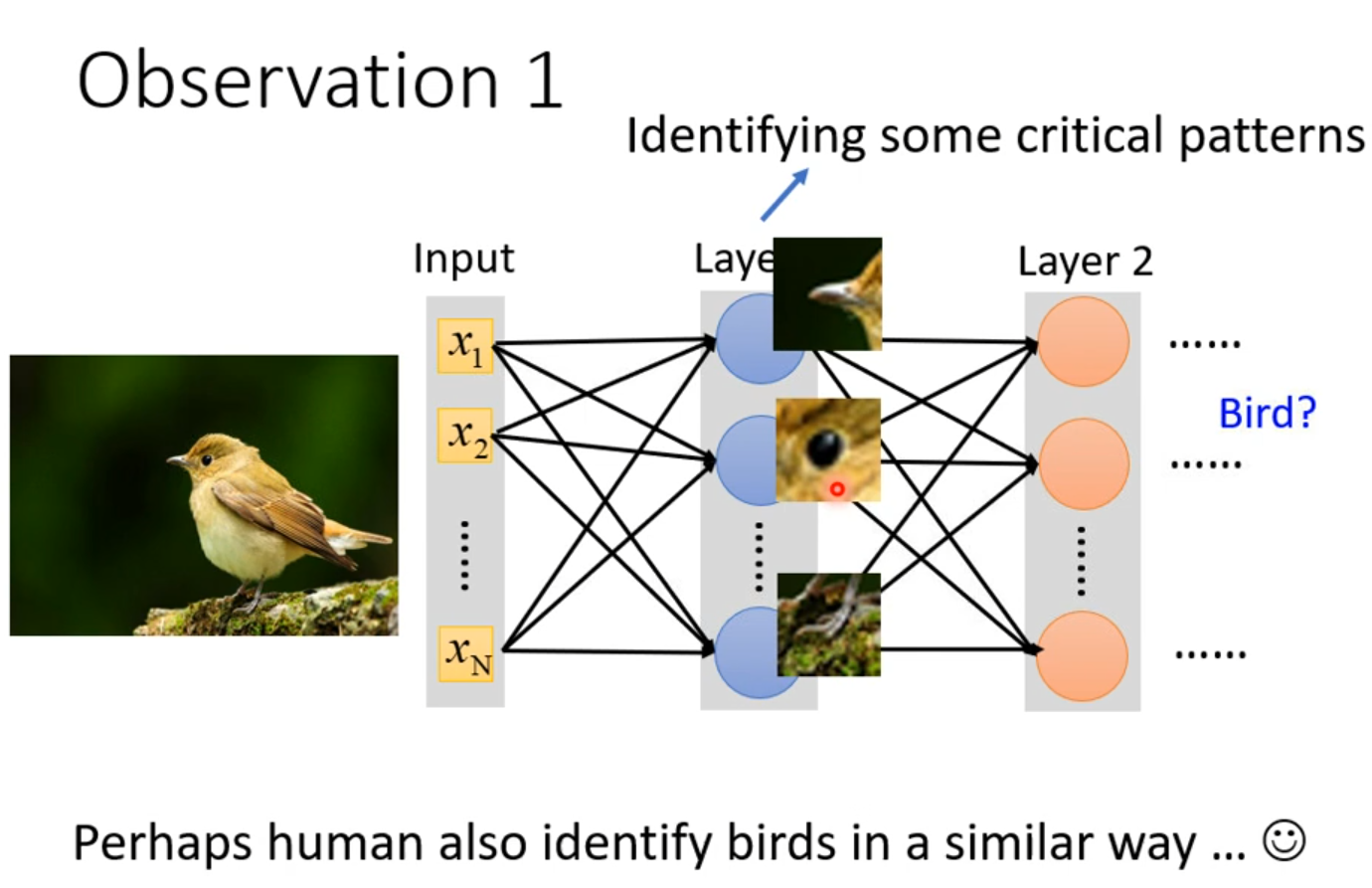
可能人类也是用这种“提取特征”的方法来识别图像的!例如:

请勿醉酒学习^^
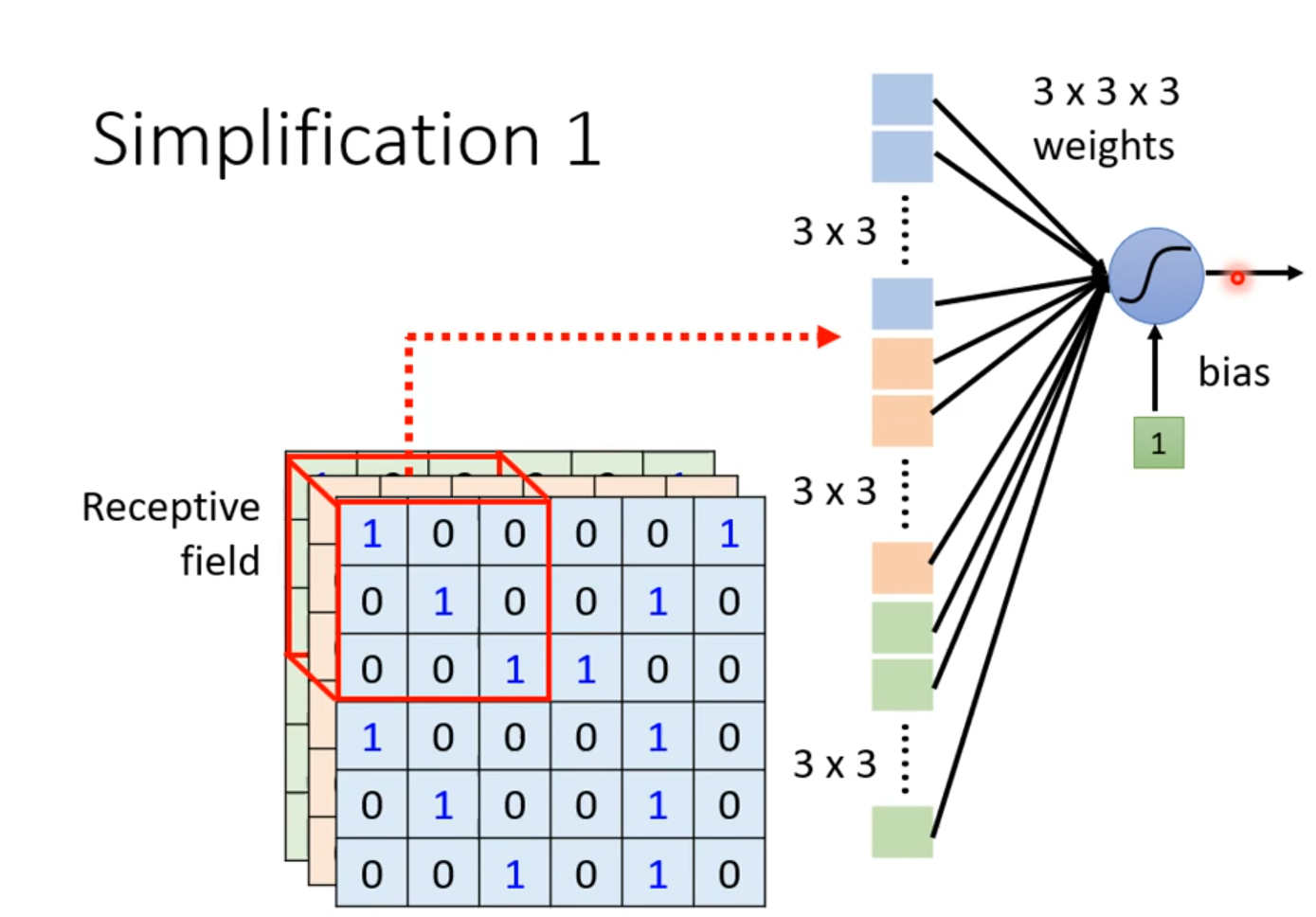
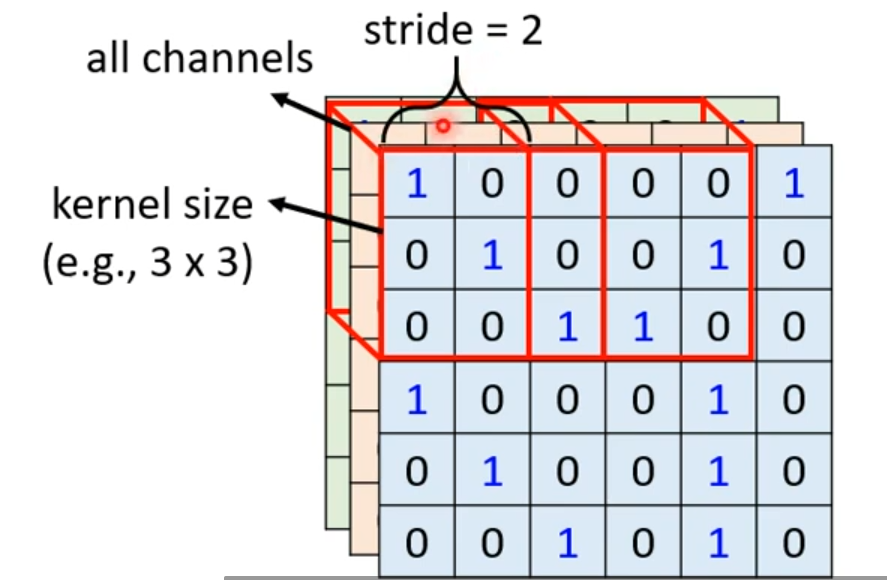
在 CNN 中,我们设计一个特定大小的区域称作“感受野”(Receptive field),每一个神经元都只需要关心自己的感受野里面有什么东西。举例:感受野为 ,则一个神经元只需要输入一个 维的向量,权重数目明显减少;
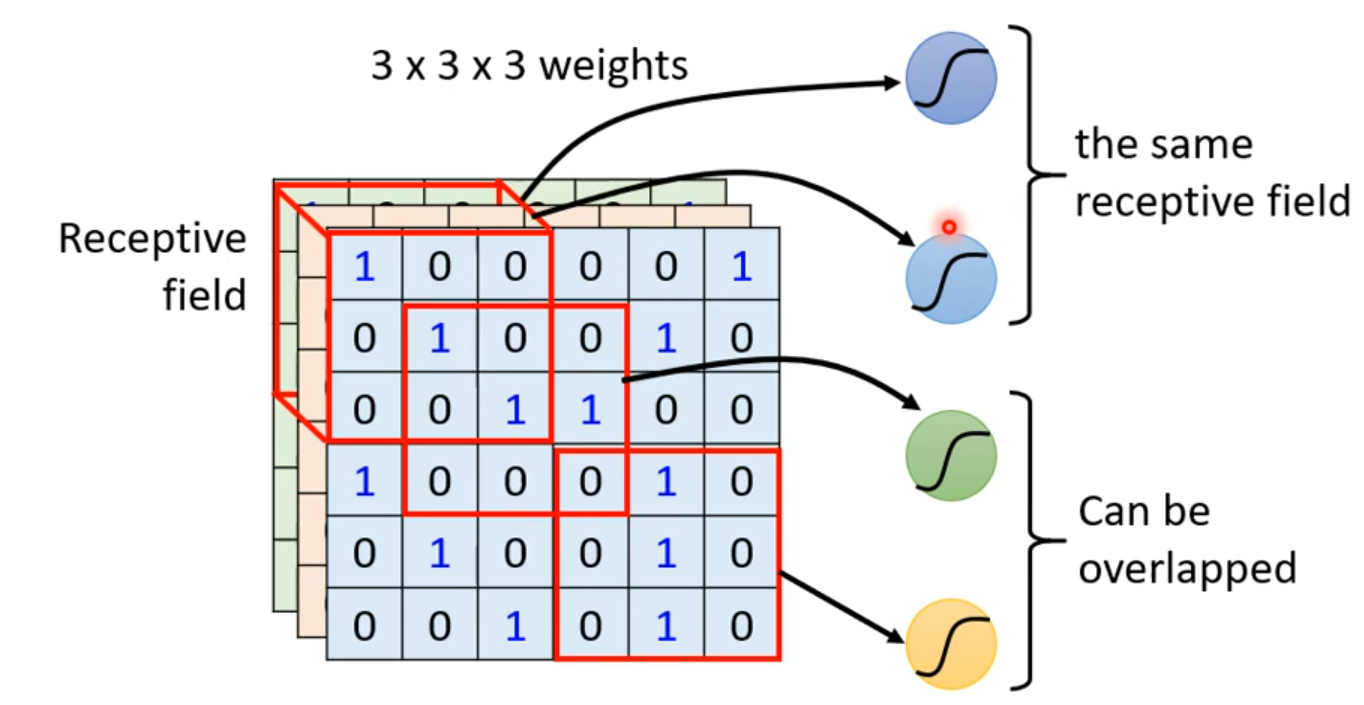
多个感受野的范围是可以重叠的,不同的神经元也可以有相同的感受野,例如:
最经典的感受野设定:
-
考虑一张图片所有的通道,而不是只考虑部分通道;
-
感受野的长和宽被称作 kernel size,如上图中感受野的 kernel size 为 ,一般不会设置很大的 kernel size;
-
同一个感受野会对应一组神经元,例如 64 个或 128 个;
-
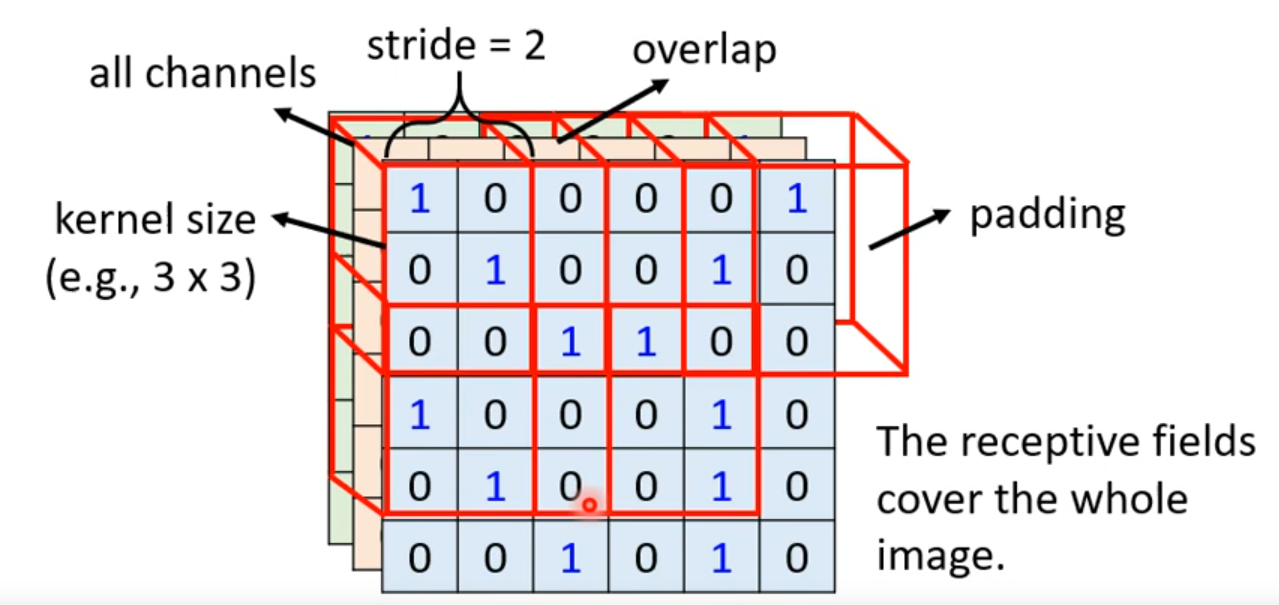
对于两个相邻的感受野,将偏移量(采样间隔)称为 stride(步幅),这是一个超参数,通常不会很大,一般设置为 1 或 2 即可;
- 当感受野超出图像范围时,我们可以向感受野中做 padding(填补),一般补充为 0。
-
-
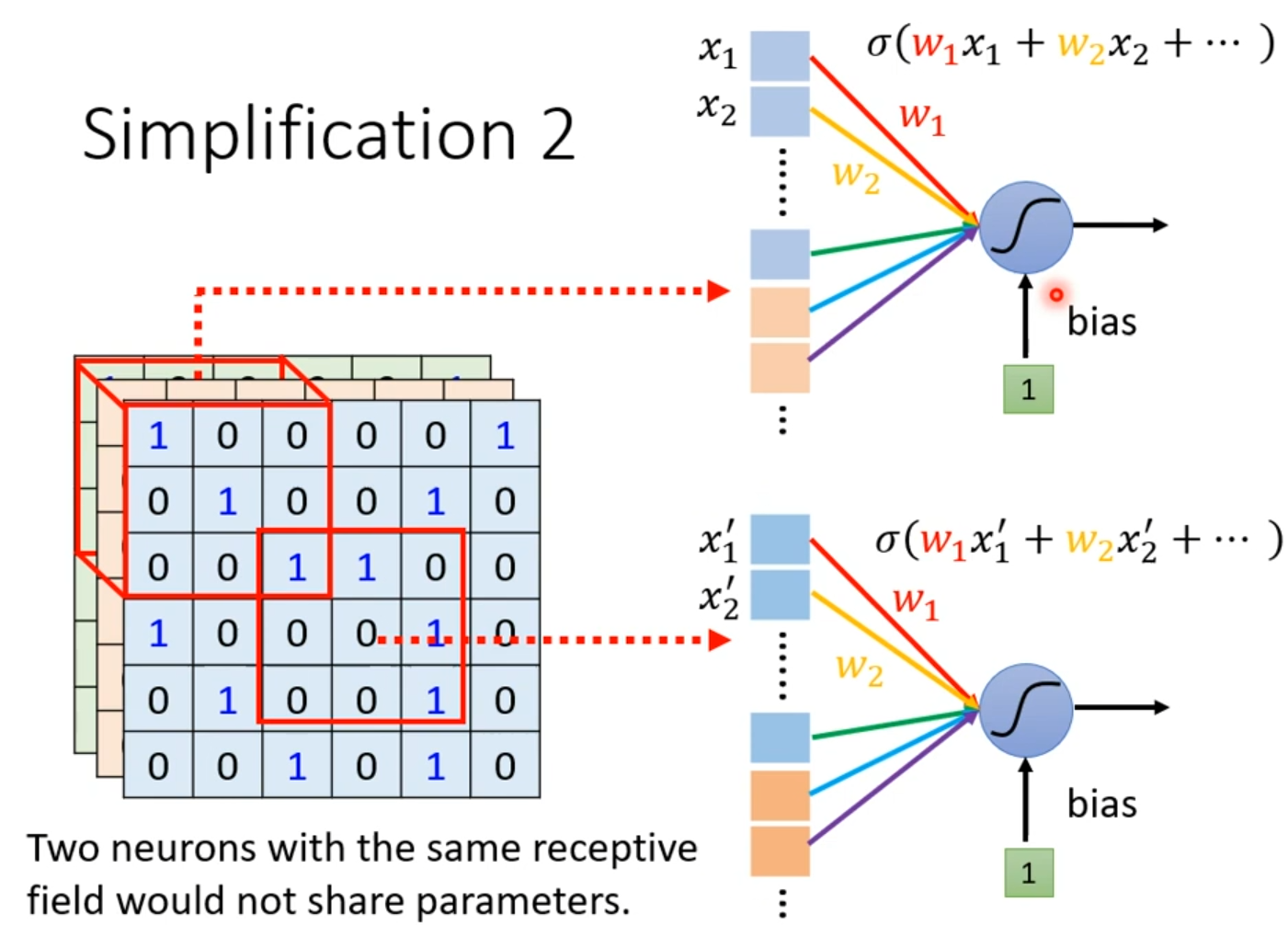
相同的特征可能会出现在图像的不同区域中,但是这些相同的特征对应的是不同的神经元,但他们做的是相同的工作。我们是否需要让每一个区域都放若干个对应不同特征的神经元?
考虑共享参数,两个对应不同感受野的对应相同特征的神经元,让他们共享相同的参数,这样参数的数量将会大大减少。由于两个神经元对应的感受野不同,他们的输入不一致,所以它们的输出也不会一样。
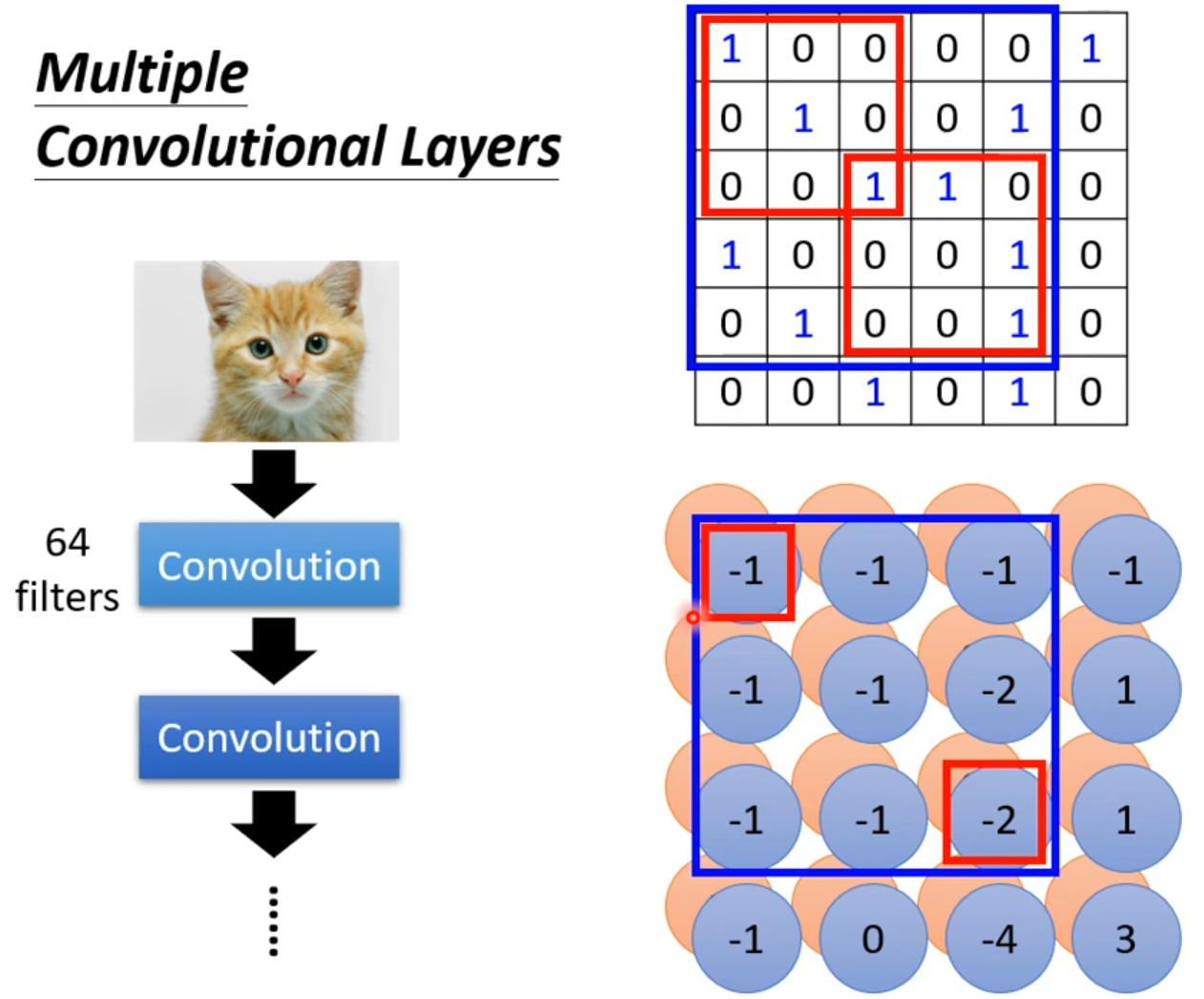
常见的共享参数的方法:对于同一层上的神经元,每一个感受野对应的神经元都只有一组参数,这组参数被称作 filter。
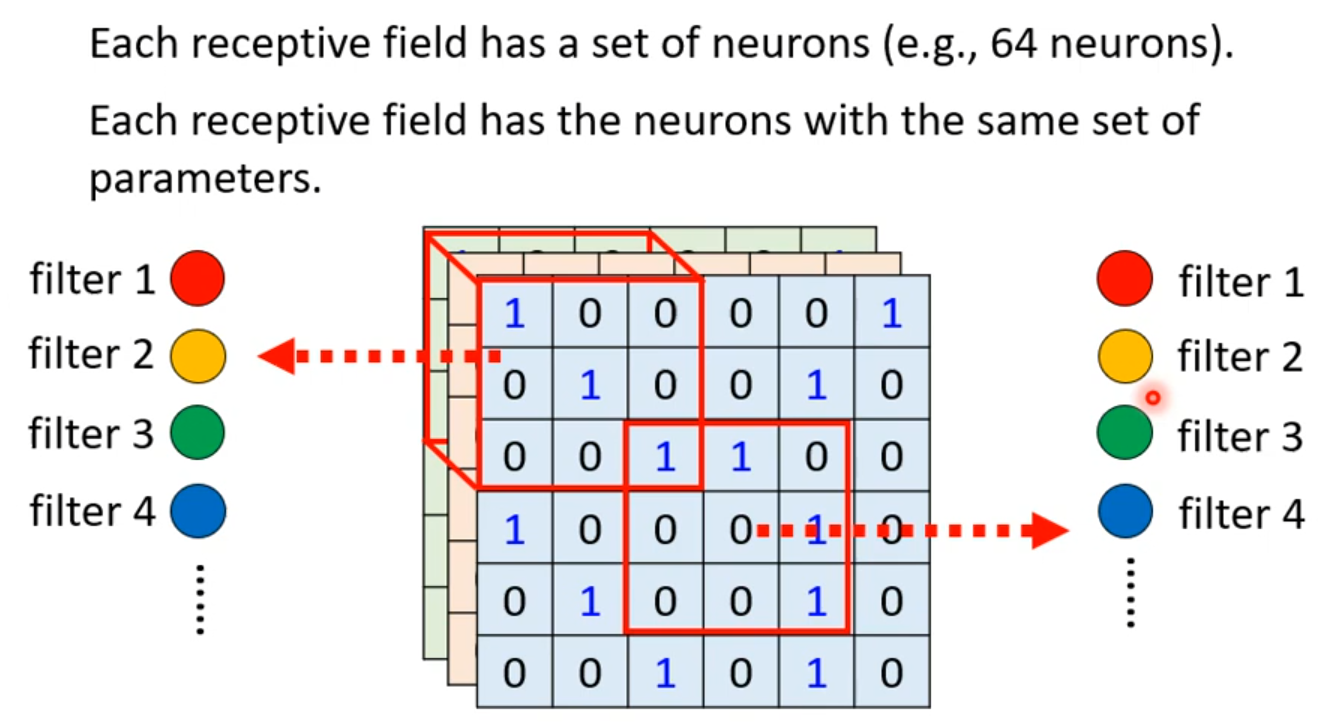
加入上述两个限制之后,我们得到的就是卷积层 Convolutional Layer。
另一种常见的解释方式:
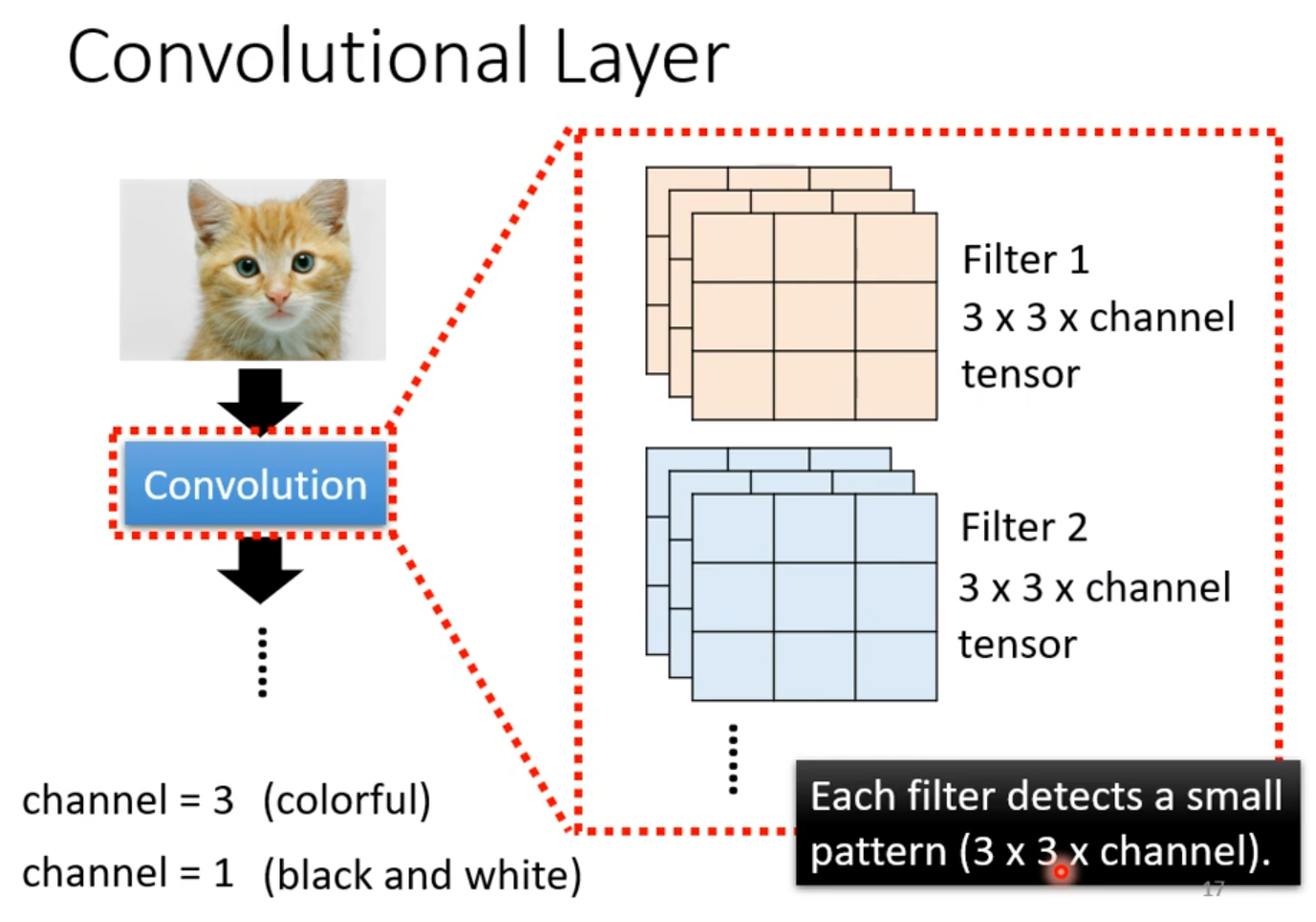
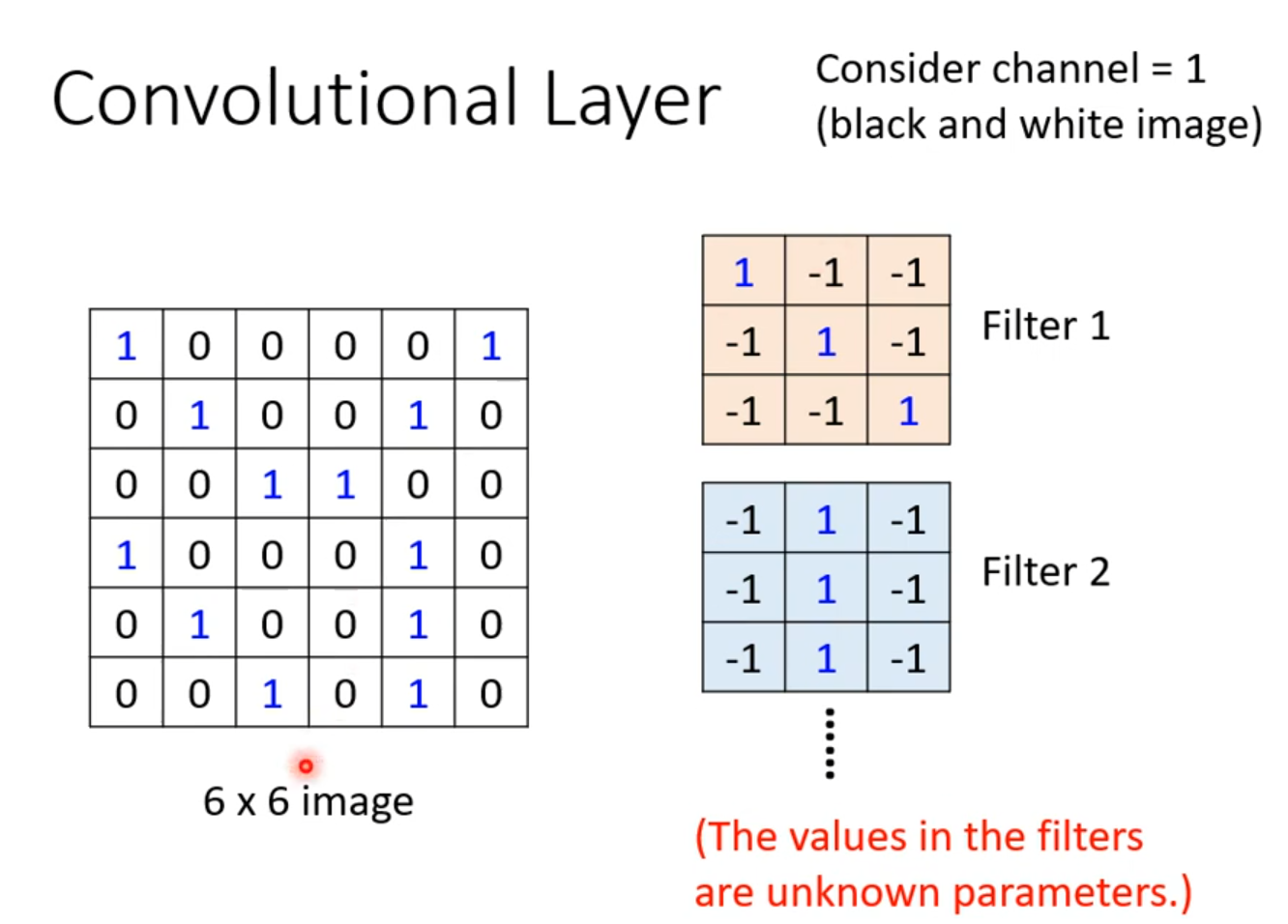
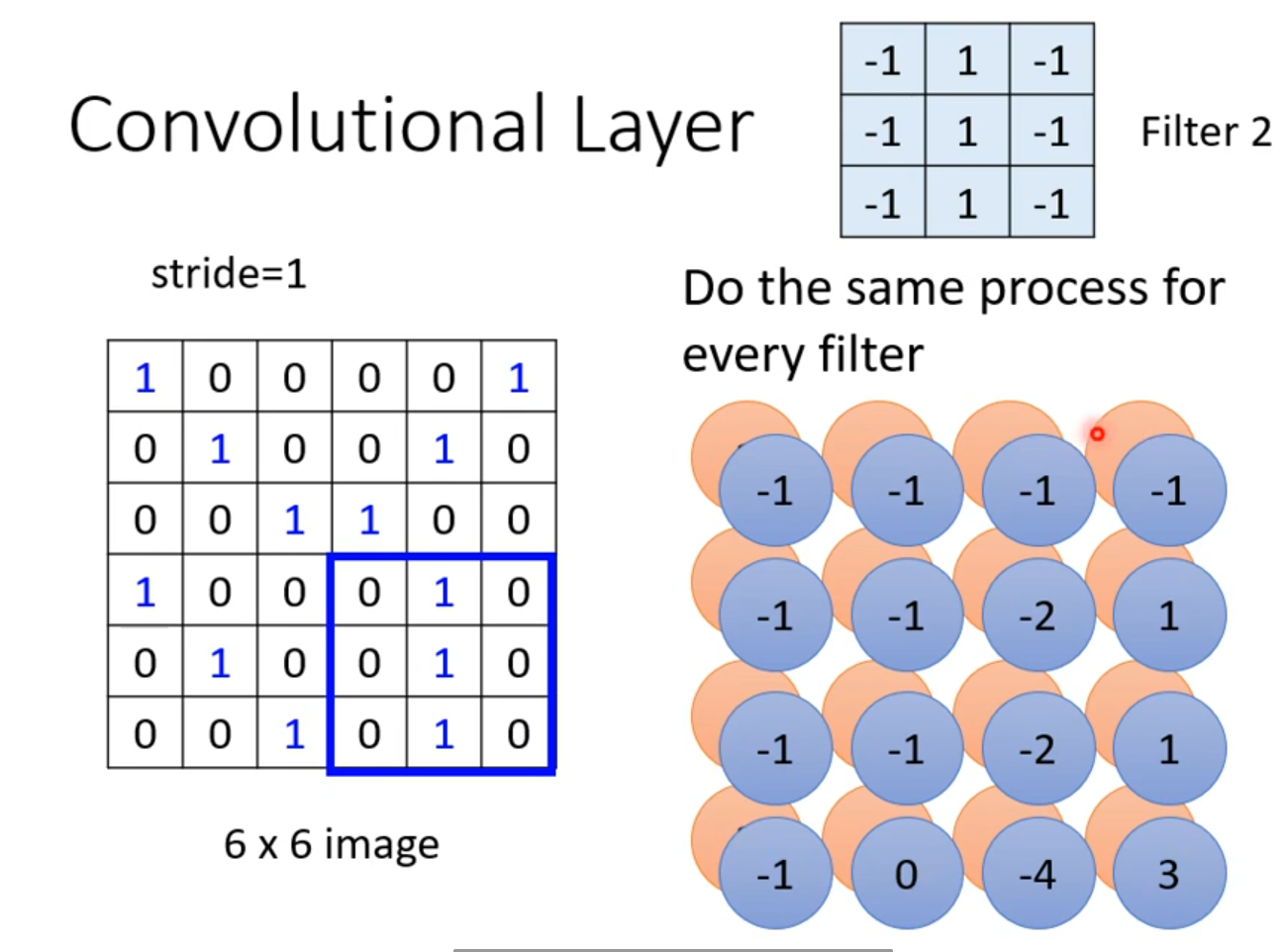
卷积后得到的结果被称做 Feature map。卷积之后得到的 Feature map 可以看做是一张新的图片,只是通道数不再是输入的通道数(1 个通道 + n 个卷积核得到 n 个通道)。
当然,卷积层也是可以叠加很多层的。
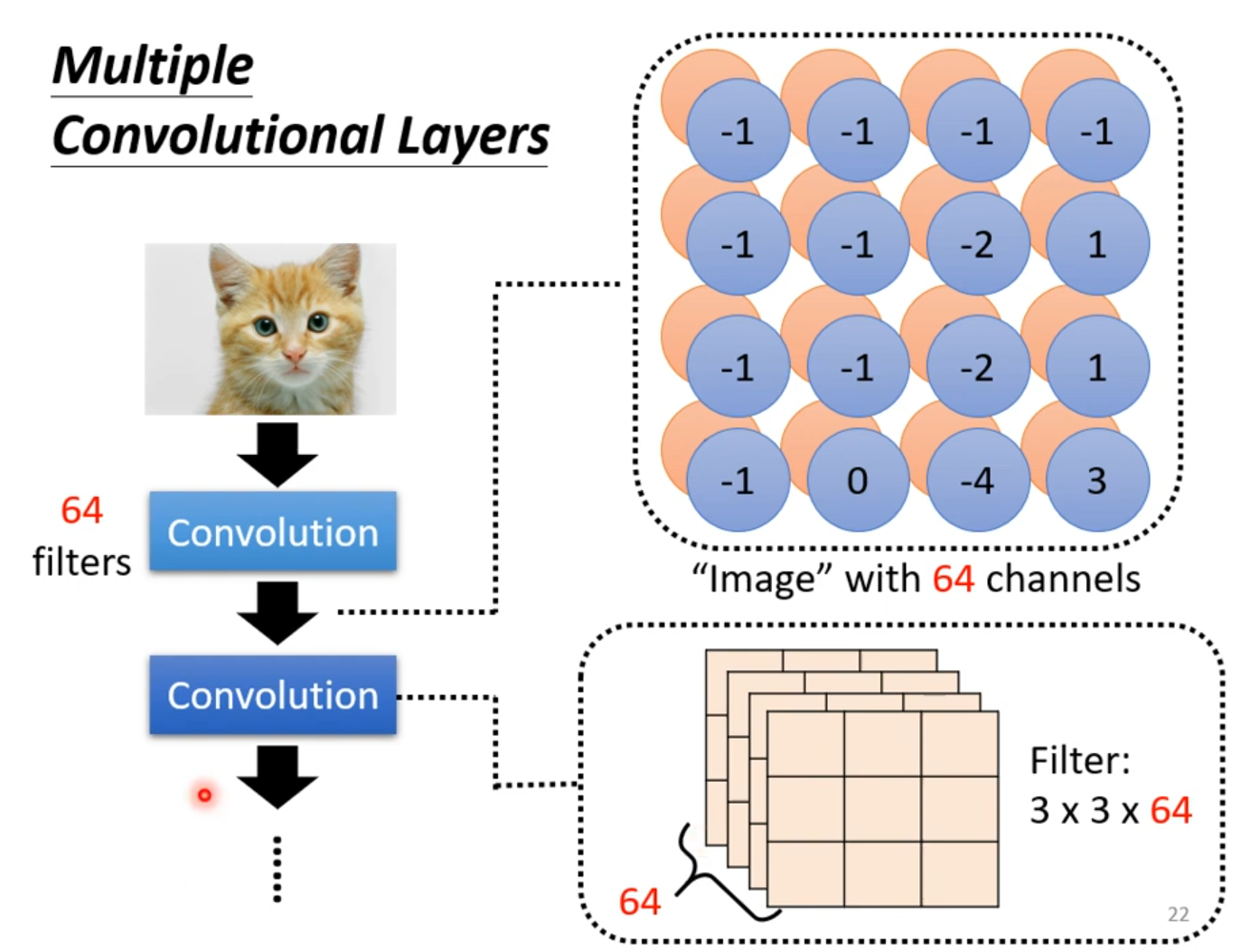
卷积层叠的越多,考虑的范围就会越来越大。
有时还可以在卷积之后做一次 ReLU 操作,使 Feature map 中不出现负数值结果:
卷积后图像大小由下面的公式进行计算:
其中,img_size 表示原图大小,filter_size 表示卷积核大小,stride 表示卷积核移动的步长。
举例:输入图片规格经过预处理后尺寸为 ,卷积核大小为 ,步长为 ,则经过卷积后得到的特征图大小为
即得到的特征图的尺寸为 。
Pooling
我们观察到,有时对于一张图片,我们对其做下采样(按照一定规律在图片中采样,使图片尺寸缩小),得到的图片特征是不变的。
根据此,我们可以对卷积得到的 Feature map 通过池化层进行压缩。
Max Pooling
我们选取一个窗口大小(通常是 或 ),然后选择步幅(通常选择 2),对每个窗口中的所有数取 ,最终得到一个特征不变但是尺寸变小的一个 Feature map。
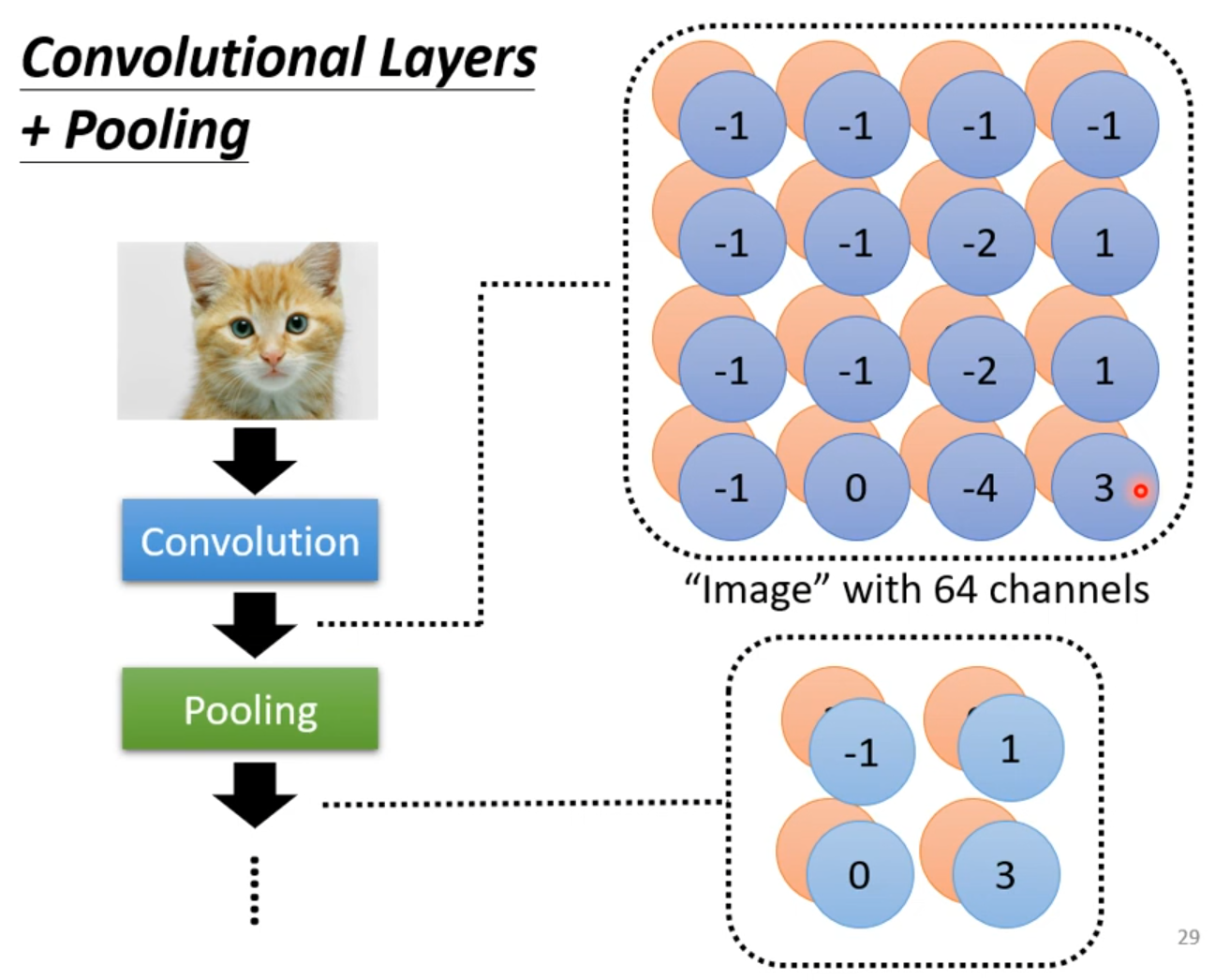
池化可以减少运算量,但相应的可能会损失掉一些细微的特征。池化可以改善结果,使之不容易过拟合。
经过几次卷积和池化后,我们将得到的 Feature map “拉直”(flatten)为一个向量,丢进全连接层来得到最终的投票结果。
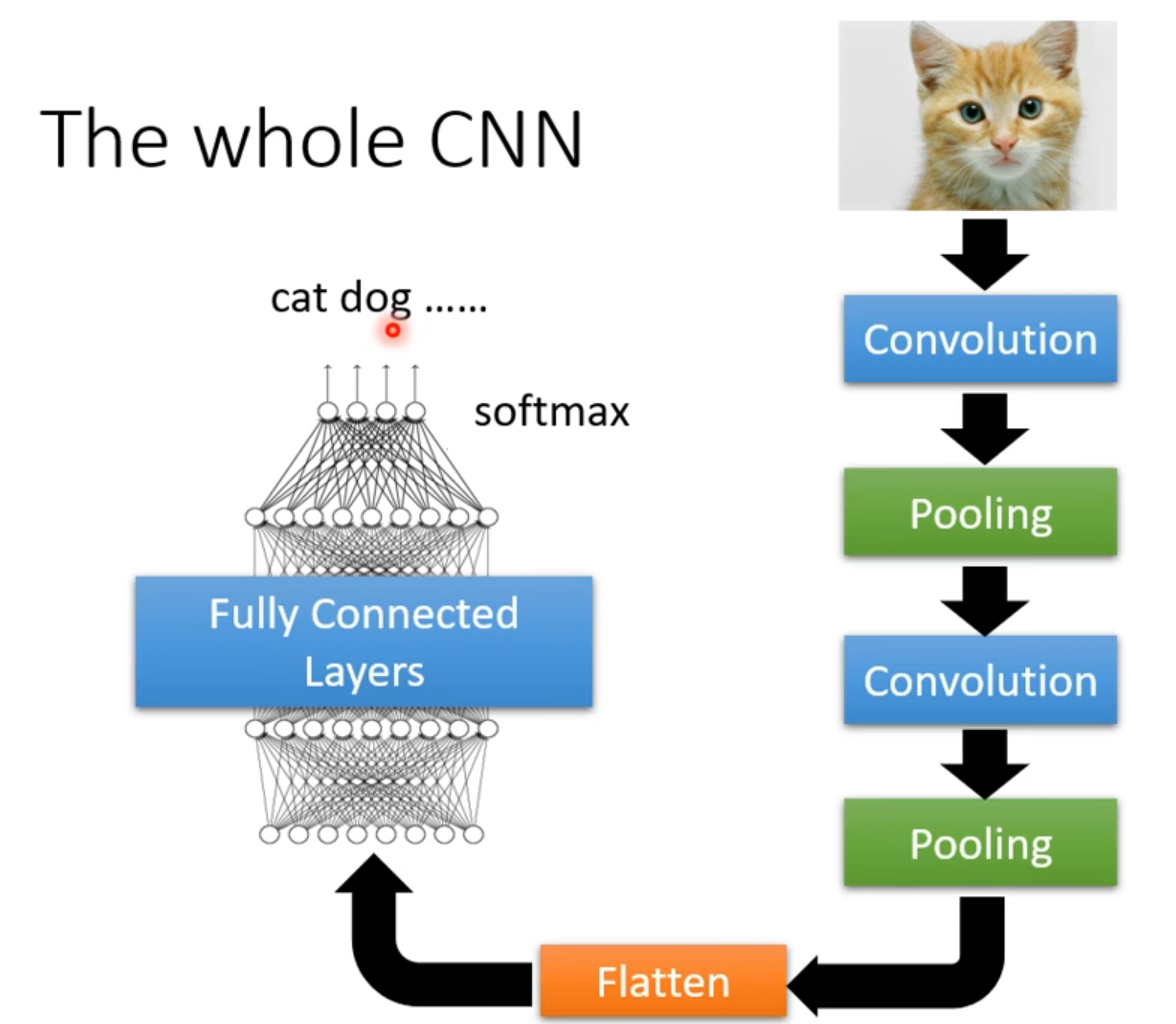
CNN 的超参数
- 卷积层:卷积核的数量;卷积核的大小;卷积核移动的步长
- 池化层:窗口的大小;窗口移动的步长
- 全连接层:神经元个数