SVM
在线性分类器中,我们知道,线性分类器的任务就是在样本空间中寻找一个超平面,将不同类别的样本分开。但是,对于特定的样本空间,我们可能能够找到很多的超平面都满足条件,那么哪个超平面是最好的呢?
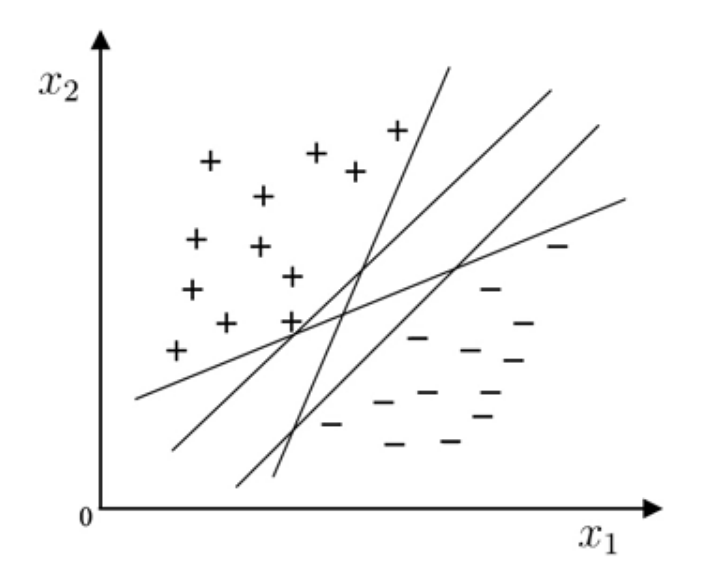
直觉上,我们认为“正中间”的是最好的,它离两类样本都比较远,拥有较好的鲁棒性和泛化能力。
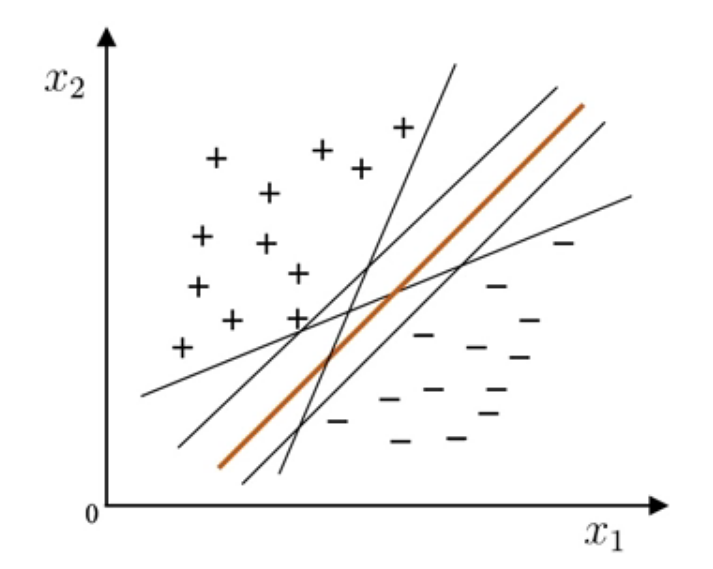
我们已经知道,超平面的方程为 wTx+b=0,为了找到“正中间”的超平面,我们要找出两类样本中距离超平面最近的那一个,计算出二者的距离,再将超平面放在中间。
两类样本中距离超平面最近的那个样本直接定义了这个超平面,我们把这几个样本称为“支持向量”:
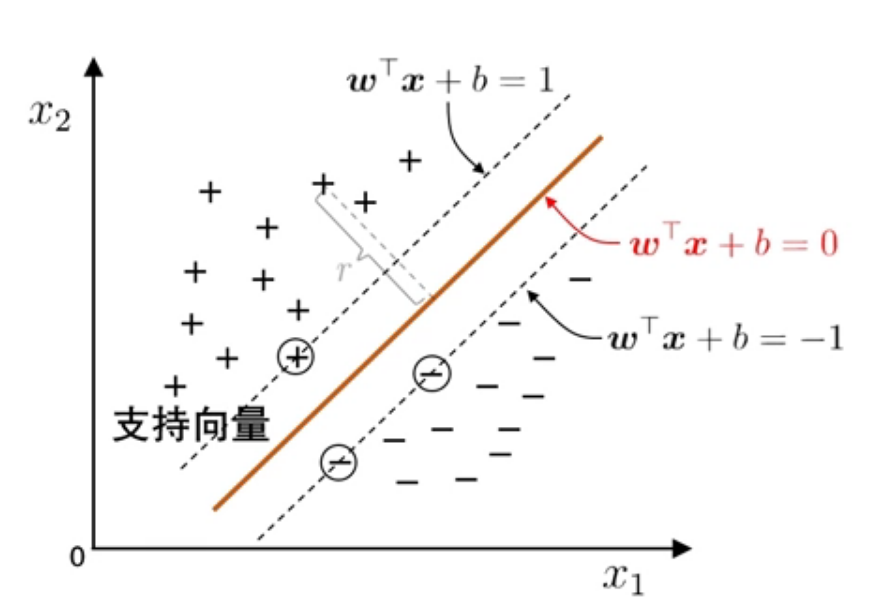
则两个支持向量之间的距离被称做“间隔”,为
γ=∥w∥2
支持向量机基本型
上面的讨论很自然的可以化为一个最优化问题:寻找参数 w 和 b,使得 γ 最大,即:
w,bargmax ∥w∥2s.t. yi(wTxi+b)≥1, i=1,2,…,m
上式中由于两个支持向量到超平面的距离为 1,所以约束中为 ≥1。
考虑对问题做等价变换,得到
w,bargmin 21∥w∥2s.t. yi(wTxi+b)≥1, i=1,2,…,m
这是一个凸二次规划问题,后文将使用拉格朗日乘子法进行解决。
不等式约束的最优化问题:
此类最优化问题的标准形式为:
xmin f(x)s.t. gi(x)≤0,hj(x)=0i∈[1,m],j∈[1,p]
其中 gi(x) 为不等式约束,hj(x) 为等式约束,m 和 p 为约束个数。
定义拉格朗日函数
L(x,λ,μ)=f(x)+i=1∑mλigi(x)+k=1∑pμkhk(x)
如果存在一组解 x∗ 满足
⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧∇xL=0hk(x∗)=0, k=1,2,⋯,pgj(x∗)≤0μj≥0μjgj(x∗)=0, j=1,2,⋯,m
则这组解 x∗ 为满足条件的一组可行解。
举例:
min x12+x22s.t.{x1+x2=1x2≤α
问题的拉格朗日函数为
L(x1,x2,λ,μ)=x12+x22+λ(1−x1−x2)+μ(x2−α)
KKT 方程组为
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧∂xi∂L=0,i=1,2x1+x2=1x2−α≤0μ≥0μ(x2−α)=0
由偏导得到
{2x1−λ=02x2−λ+μ=0
代入 x1+x2=1 得到
⎩⎪⎪⎨⎪⎪⎧x1=4μ+21x2=−4μ+21
由 x2−α≤0 得到 μ≥2−4α,下面对 α 进行讨论:
- 若 2−4α<0 即 α>21 时,所有的 KKT 条件都能满足,此时得到一组解 x1∗=x2∗=21,目标函数的最小值为 21;
- 若 α=21 时,也能满足所有的 KKT 条件,此时的解同上;
- 若 α<21 时,μ>0,此时必须有 x2=α,故 x1=1−α,目标函数的极小值为 α2+(1−α)2。
注意到 KKT 条件中的其中一个为 μg(x)=0 且 μ≥0,则当 g(x)<0 时,μ=0 一定成立;而当 g(x)=0 时,原问题变为若干个等式约束的最优化问题,必定有 μ>0。
根据定义,支持向量是位于间隔边缘上的点,此时有 g(x)=0,即 μ>0,于是有结论:对应 μ>0 的点是支持向量。
核化法
核化法基于一个非常朴素的思考:前面的所有讨论都是基于训练样本是线性可分的基础上的,即我们可以找到一个超平面将训练样本正确分类。但在现实任务中,原始的样本空间可能是非线性可分的,即找不到一个能正确划分两类样本的超平面。
此时我们通过核化法将数据映射到一个更高维的特征空间,使得样本在特征空间中线性可分,从而完成分类任务。
定理:如果原始空间是有限维的,那么必定存在一个高维特征空间使样本线性可分。
设样本 x 映射后的向量为 ϕ(x),划分超平面为 f(x)=wTϕ(x)+b,则原始的最优化问题变为
w,bmin 21∥w∥2s.t. yi(wTϕ(xi)+b)≥1, i=1,2,⋯,m
其对偶问题为
αmax i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjϕ(xi)Tϕ(xj)s.t. i=1∑mαiyi=0,αi≥0,i=1,2,⋯,m
预测方程为
f(x)=wTϕ(x)+b=i=1∑mαiyiϕ(xi)Tϕ(x)+b
但是我们发现了一个计算上的问题:由于 ϕ(x) 是一个维数非常高甚至无限的向量,两向量内积 ϕ(xi)Tϕ(xj) 可能难以计算甚至无法计算,开销非常大。注意到,两个高维向量始终只以内积的形式出现,如果我们能找到一个可以代替内积的东西,同时比内积好计算,那么这个问题就可以解决了。
此时我们引入核函数 κ(xi,xj)=ϕ(xi)Tϕ(xj),通过此我们可以绕过显式考虑特征映射和计算高维内积困难的问题。“核函数选择”成为决定支持向量机性能的关键。
常用的核函数有以下几种:
| 名称 |
表达式 |
参数 |
| 线性核 |
κ(xi,xj)=xiTxj |
|
| 多项式核 |
κ(xi,xj)=(xiTxj+r)d |
r 为偏移量,d≥1 为多项式次数 |
| 高斯核 |
κ(xi,xj)=exp(−2σ2∣xi−xj∣2) |
σ>0 为高斯核的带宽 |
| 拉普拉斯核 |
κ(xi,xj)=exp(−σ∣xi−xj∣) |
σ>0 |
| Sigmoid 核 |
κ(xi,xj)=tanh(βxiTxj+θ) |
β>0,θ<0 |
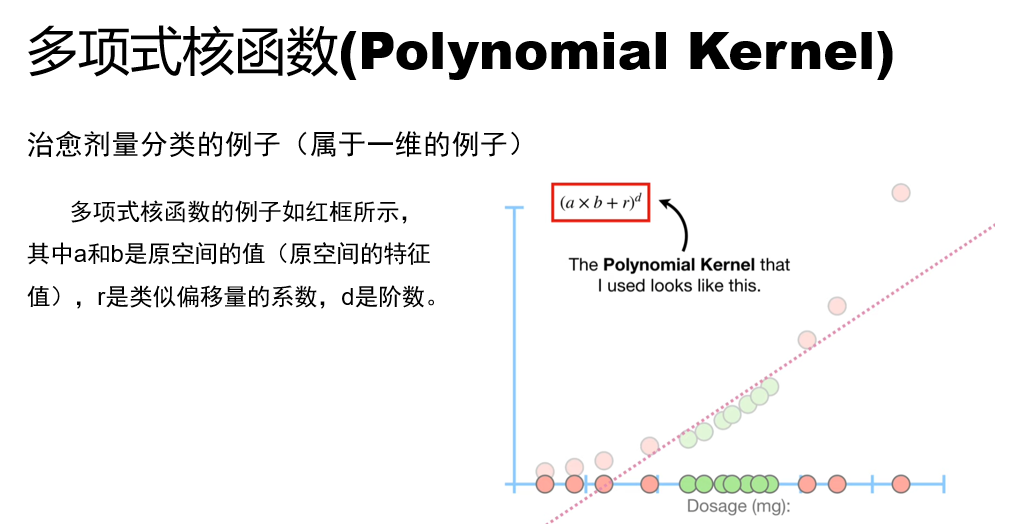
例:假设 r=1,d=2,则多项式核函数为
(a×b+1)2=(a×b+1)(a×b+1)=a2b2+2ab+1=(2a,a2,1)⋅(2b,b2,1)
映射函数为
{ϕ:R1→R3(x)→(z1,z2,z3)=(2x,x2,1)
另一个例:当映射函数 ϕ(x)=(x12,2x1x2,x22) 时,多项式核函数的 r 和 d 分别是多少?
写做两个向量内积形式为
ϕ(x)ϕ(x′)=x1x1′2+2x1x2x1′x2′+x2x2′2=(x1x1′+x2x2′)2=(x×x′)2
所以 r=0,d=2。
根据核函数我们可以推导得到特征空间中两个向量间的距离和夹角:
-
两向量间的距离为
∥ϕ(x)−ϕ(x′)∥=(ϕ(x)−ϕ(x′))T(ϕ(x)−ϕ(x′))=ϕ(x)Tϕ(x)−ϕ(x)Tϕ(x′)−ϕ(x′)Tϕ(x)+ϕ(x′)Tϕ(x′)=κ(x,x)−κ(x,x′)−κ(x′,x)+κ(x′,x′)=κ(x,x)−2κ(x,x′)+κ(x′,x′)
-
两向量间的夹角余弦为
cosθ=∥ϕ(x)∥∥ϕ(x′)∥ϕ(x)⋅ϕ(x′)=ϕ(x)Tϕ(x)ϕ(x′)Tϕ(x′)ϕ(x)Tϕ(x′)=κ(x,x)κ(x′,x′)κ(x,x′)
以二分类为例,升维后我们找到两类数据的中心:
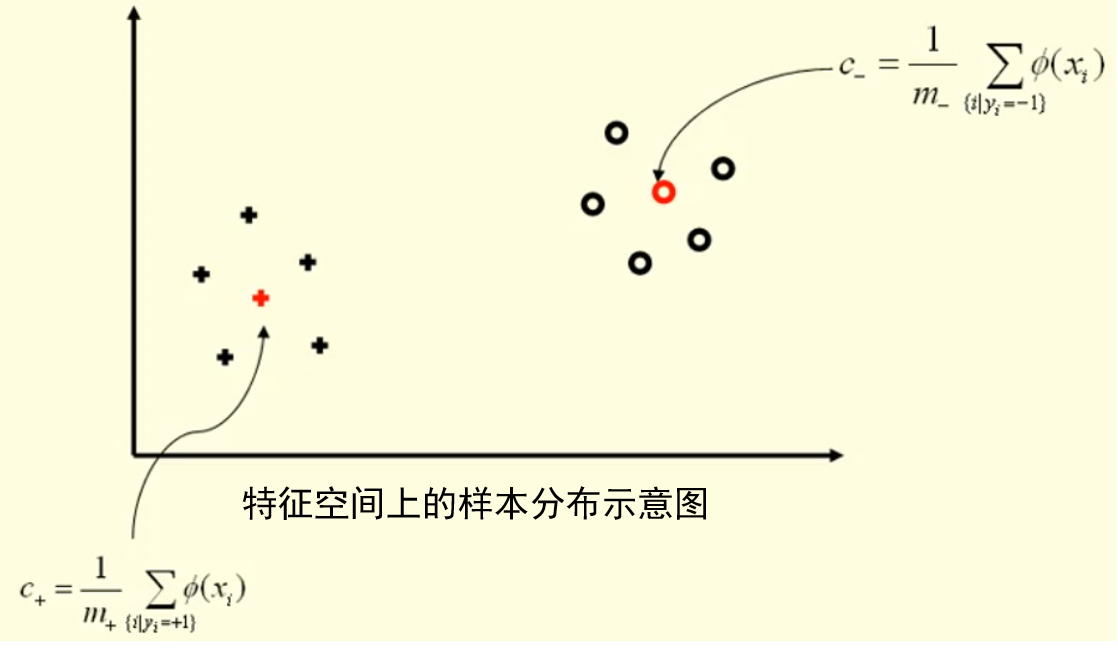
根据两类数据的中心可以算出两个中心间的向量 w=c+−c−:
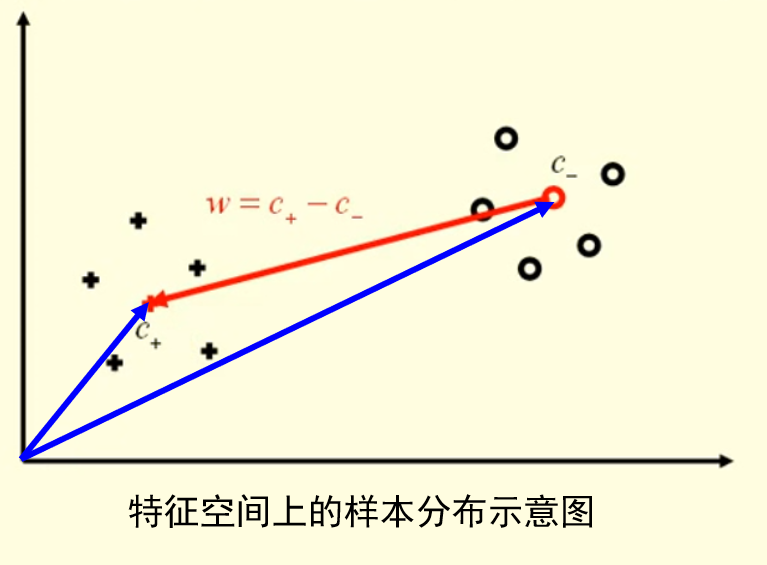
再计算出分隔这两类的超平面 c=21(c++c−):
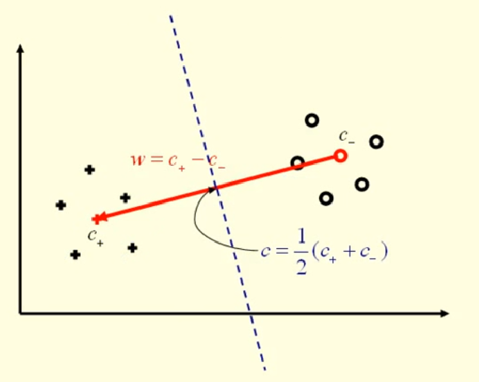
对于一个测试数据 (x,y)→(ϕ(x),y):
-
当数据属于正类时,有
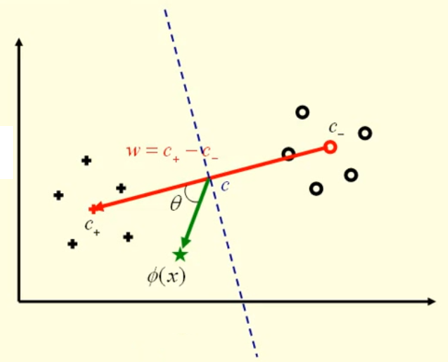
即
0≤θ<2π⟺0<cosθ≤1⟺κ(ϕ(x)−c,w)≥0
-
当数据属于负类时,由上面讨论有 κ(ϕ(x)−c,w)≤0。
综上,数据类别为 y=sign(κ(ϕ(x)−c,w)),现在考虑如何计算:
-
若已知 ϕ(x)时,那么可以直接进行分类计算;
-
在不知道 ϕ(x) 时,可以通过核函数进行计算:
κ(ϕ(x)−c,w)=wT(ϕ(x)−c)=(c+−c−)Tϕ(x)−21(c+−c−)T(c++c−)=⎝⎛m+1(i∣yi=1)∑ϕ(xi)−m−1(i∣yi=−1)∑ϕ(xi)⎠⎞Tϕ(x)−21(c+Tc+−c−Tc−)=⎝⎛m+1(i∣yi=1)∑ϕ(xi)Tϕ(x)−m−1(i∣yi=−1)∑ϕ(xi)Tϕ(x)⎠⎞−21⎝⎛m+1(i∣yi=1)∑ϕ(xi)T⋅m+1(j∣yj=1)∑ϕ(xj)−m−1(i∣yi=−1)∑ϕ(xi)T⋅m−1(j∣yj=−1)∑ϕ(xj)⎠⎞=⎝⎛m+1(i∣yi=1)∑κ(xi,x)−m−1(i∣yi=−1)∑κ(xi,x)⎠⎞−21⎝⎛m+21(i∣yi=1)∑(j∣yj=1)∑κ(xi,xj)−m−21(i∣yi=−1)∑(j∣yj=−1)∑κ(xi,xj)⎠⎞
我们发现,即便是我们只有核函数,我们仍然能够在高维空间(特征空间)里面进行分类。
综上,映射函数 ϕ 不是必须的,只有核矩阵
⎣⎢⎢⎢⎢⎡κ(x1,x1)κ(x2,x1)⋮κ(xn,x1)κ(x1,x2)κ(x2,x2)⋮κ(xn,x2)⋯⋯⋮⋯κ(x1,xn)κ(x2,xn)⋮κ(xn,xn)⎦⎥⎥⎥⎥⎤
是半正定时,κ(⋅,⋅) 才是一个可使用的核函数;给定一个 ϕ 也能找到其对应的 κ,给定一个 κ 也能找到一个对应的特征空间使得 κ 对应空间中的向量内积。
半正定:给定一个大小为 n×n 的实对称矩阵 A,若对于任意长度为 n 的向量 x,有 xTAx≥0 恒成立,则称矩阵 A 是一个半正定矩阵。
硬间隔 SVM
在上面的讨论中,我们得到 hard-margin SVM 的最优化问题:
w,bargmin 21∥w∥2s.t. yi(wTxi+b)≥1, i=1,2,…,m
构造拉格朗日函数:
L(w,b,α)=21wTw+i=1∑mαi(1−yi(wTxi+b))
分别对 w、b 求偏导可得
\begin{aligned}
\dfrac{\part L}{\part \boldsymbol w} &= 0 \Longrightarrow \boldsymbol w = \sum_{i=1}^m \alpha_iy_i\boldsymbol x_i \\
\dfrac {\part L}{\part b} &= 0 \Longrightarrow \sum_{i = 1}^m \alpha_iy_i = 0
\end{aligned}
将上述两式代入拉格朗日函数得
L(α)=21wTw+i=1∑mαi−i=1∑mαiyiwTxi−i=1∑mαiyib=21(i=1∑mαiyixiT)(j=1∑mαjyjxj)+i=1∑mαi−i=1∑mαiyi(j=1∑mαjyjxjT)xi=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
结合上面对 b 的偏导得到的约束,我们得到原最优化问题的对偶问题:
αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t. i=1∑mαiyi=0,αi≥0, i=1,2,⋯,m
下面证明上式存在最大值:

若推广至高维只需要 x→ϕ(x),xiTxj→κ(xi,xj)。
软间隔 SVM
由于 hard-margin SVM 无法容忍无法线性可分的情况,可能在确定超平面时出现过拟合的情况,于是我们允许一部分异类样本落入另一侧的区域,形成 soft-margin SVM。此时最优化问题可写为
w,b,ξmin 21wTw+Ci=1∑mξi,C>0s.t. ξi≥0,yi(wTxi+b)≥1−ξi, i=1,2,⋯,m
其中 ξi 被称为松弛变量。
当 C 增大时,∑ξi 必定减小,ξi 必定减小,则由限制可知间隔减小。
上问题的拉格朗日函数为
L(w,b,ξ,α,β)=21wTw+Ci=1∑mξi+i=1∑mαi[1−ξi−yi(wTxi+b)]−i=1∑mβiξi
令上式分别对 w、b 和 ξ 求偏导可得
\begin{aligned}
\dfrac {\part L}{\part \boldsymbol w} &= 0 \Longrightarrow \sum_{i = 1}^m \alpha_iy_i\boldsymbol x_i = \boldsymbol w \\
\dfrac {\part L}{\part b} &= 0 \Longrightarrow \sum_{i = 1}^m \alpha_iy_i = 0 \\
\dfrac {\part L}{\part \xi_i} &= 0 \Longrightarrow C - \alpha_i - \beta_i =0 \rightarrow 0 \leq \alpha_i, \beta_i \leq C
\end{aligned}