词法分析
我们令 id 表示以字母开头的包含字母、数字的字符串,id 定义了一个集合,称之为语言(Language)。
id 中使用了字母、数字等符号集合,称之为字母表(Alphabet)。
语言中的每个元素(标识符)称为串(String)。
字母表 Σ 是一个有限的符号集合。
字母表 Σ 上的串(s)是由 Σ 中的符号组成的一个有穷序列。ϵ 表示空串,其长度 ∣ϵ∣=0。
在两个串 x 和 y 上可以做连接运算 xy,例如:x=dog,y=house→xy=doghouse。特殊的,sϵ=ϵs=s。
由连接运算可以定义指数运算 si:
s0si≜ϵ≜ssi−1,i>0
意为自连接 i 次。
语言是给定字母表 Σ 上一个任意的可数的串集合。当集合中没有串时,称为空语言 ∅。
注意区分 ∅ 和 {ϵ}。
语言举例:id: {a,b,c,a1,a2,…};ws: {blank,tab,newline};if: {if}。
由于语言是串的集合,因此我们可以通过对集合的操作构造新的语言。
例如:
- L 和 M 的并:L∪M={s∣s∈L∨s∈M};
- L 和 M 的连接:LM={xy∣x∈L∧y∈M};
- L 的幂:Li={s1s2…si∣si∈L},即 L 中的任意元素连接 i 次;
- L 的 Kleene 闭包:L∗=⋃i=0∞Li;
- L 的正闭包:L+=⋃i=1∞Li。
可以注意到
L∗L+=L0⋃L+=LL∗=L∗L
闭包运算允许我们通过有限的集合构造无穷集合。
令 L 为所有大小写字母的集合,D 为所有数字的集合,则 L(L∪D)∗ 的含义为以字母开头的任意字母和数字组合的字符串。
对照语言举例,发现 id 的定义即为 L(L∪D)∗。
如何让 parser 知道 id 是这样定义的?
正则表达式
每个正则表达式 r 对应着一个正则语言 L(r),正则表达式是语法,正则语言是语义。
正则表达式对应的正则语言:
L(ϵ)={ϵ}
L(a)={a},∀a∈Σ
L((r))=L(r)
L(r∣s)=L(r)⋃L(s)L(rs)=L(r)L(s)L(r∗)=(L(r))∗
正则表达式中的表达式及其匹配:
| 表达式 |
匹配 |
例子 |
| c |
单个非运算符字符 c |
a |
| \c |
字符 c 的字面值 |
\∗ |
| “s” |
串 s 的字面值 |
“∗∗” |
| . |
除换行符以外的任何字符 |
a.∗b |
| ^ |
一行的开始 |
^abc |
| $ |
一行的结尾 |
abc$ |
| [s] |
字符串 s 中的任意一个字符 |
[abc] |
| [^s] |
不在字符串 s 中的任意一个字符 |
[^abc] |
| r∗ |
和 r 匹配的零个或多个串连接成的串 |
a∗ |
| r+ |
和 r 匹配的一个或多个串连接成的串 |
a+ |
| r? |
零个或一个 r |
a? |
| r{m,n} |
最少 m 个,最多 n 个 r 的重复出现 |
a{1,5} |
| r1r2 |
r1 后加上 r2 |
ab |
| r1∣r2 |
r1 或 r2 |
a∣b |
| (r) |
与 r 相同 |
(a∣b) |
| r1/r2 |
后面跟有 r2 时的 r1 |
abc/123 |
| r{n} |
恰好 n 个 r |
a{5} |
有些固定的匹配可以简记:
- \w → [A-Za-z0-9_];
- \W → [^A-Za-z0-9_];
- \d → [0-9];
- \l → [a-z];
- \_s → [ \t\r\n\v\f];
- \S → [^ \t\r\n\v\f];
- \u → [A-Z]。
Q:(0∣(1(01∗0)∗1))∗ 表达的是什么含义?
A:通过 regex101: build, test, and debug regex 找规律,给定若干01串,其匹配的是十进制下 3 的倍数的二进制,即答案集合为
{(x)2∣(x)10≡0(modp)}
自动机
自动机具有两大要素:状态集 S 以及状态转移函数 δ。
Q:如何定义一个自动机的表达能力或计算能力?
A:每个自动机 A 可以表示一个语言 L(A),通过语言集合的大小来确定表达能力。
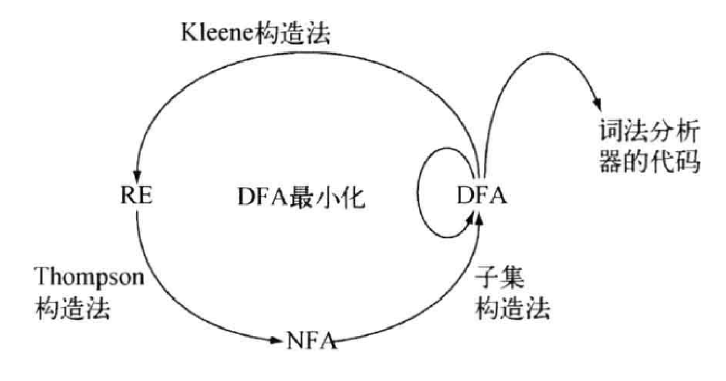
我们希望通过若干的正则表达式 RE,最终得到一个词法分析器。
NFA
非确定性有穷自动机(NFA)A 是一个五元组
A=(Σ,S,S0,δ,F)
包含:
- 字母表 Σ,其中 ϵ∈/Σ;
- 有穷的状态集合 S;
- 唯一的初始状态集合 S0∈S;
- 状态转移函数 δ,满足
δ:S×(Σ∪{ϵ})→2S
这表示当前处于某个状态,并找到了一个字母表中的字符或空串,接下来将转移到 S 的幂集。
δ(S,a) 表示从状态 S 沿字母 a 的边走向的状态,这些状态被称为后继状态。
S 的幂集是 S 的所有子集构成的集合。
- 接受(结束/终止)状态集合 F⊆S,可以为空。
NFA 的非确定性:
- 状态转移不唯一:δ(S,a) 是一个集合;
- 若存在 δ(S,ϵ),则某个状态 S 可以通过 δ(S,ϵ) 自发地转移至另一个状态 S′;
- 初始状态是一个集合。
注意到 δ 是一个函数,意味着对于定义域中的每个元素,都应当有一个对应的映射,于是约定:所有没有对应出边的字符都默认指向一个不存在的“空状态” ∅。
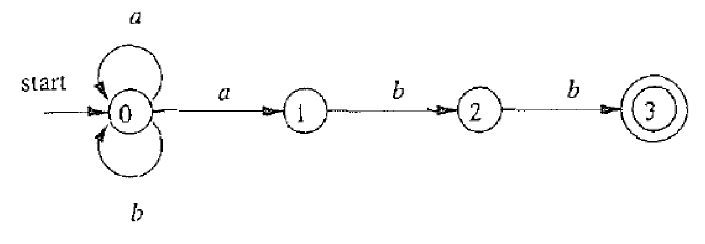
对于上方的 NFA,可以给出如下的状态转换表:
| 状态 |
a |
b |
ϵ |
| 0 |
{0, 1} |
{0} |
∅ |
| 1 |
∅ |
{2} |
∅ |
| 2 |
∅ |
{3} |
∅ |
| 3 |
∅ |
∅ |
∅ |
NFA 可以识别(接受或拒绝) Σ 上的字符串。
(非确定性)有穷自动机 A 接受字符串 x 当且仅当存在一条从开始状态 s0 到某个接受状态 f∈F、标号(按顺序记录每条边上的字符)为 x 的路径。
因此,A 定义了一种语言 L(A),为 A 能接受的所有字符串构成的集合。对于上方的 NFA,不难发现 aabb∈L(A),ababab∈/L(A)。
上方的 NFA 表达的语言 L(A)=L((a∣b)∗abb),此时我们将 NFA 转化为了正则表达式。
对于一个自动机 A,我们关心两个基本问题:
- Membership:给定字符串 x,x∈L(A)?
- L(A) 究竟是什么?
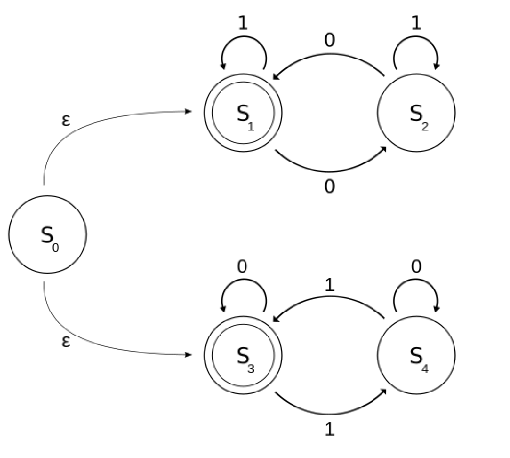
上半部分对应的正则表达式为 (1∗∣01∗01∗)∗,下半部分对应的正则表达式为 (0∗∣10∗10∗)∗,即 L(A) 是包含偶数个 0 或偶数个 1 的 01 串。
DFA
确定性有穷自动机(DFA)和 NFA 不同在于状态转移函数 δ:
δ:S×Σ→S
即,不能通过空串转移状态,对于每次转移,到达的状态都是唯一的。
同时,初始状态不再是一个集合 S0,而是一个唯一的状态 s0。
我们约定,所有没有对应出边的字符默认指向一个“死状态”,进入死状态后接受任何字符都会回到死状态。
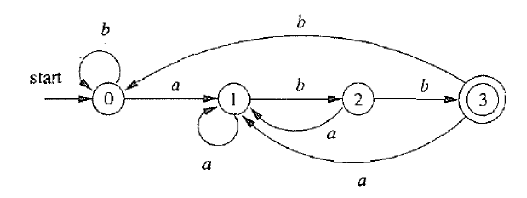
对于这个 DFA,不难得到 aabb∈L(A),ababab∈/L(A)。
判断 L(A) 对应的正则表达式似乎成为了一件难事!这个 DFA 对应的 L(A)=L((a∣b)∗abb)。
是否发现问题?这个 DFA 和上面的 NFA 表达了同一个 L(A)!
这表明:NFA 简便易于理解,便于描述语言 L(A);DFA 易于判断 x∈L(A),适合产生词法分析器。
所以我们用 NFA 描述语言,用 DFA 实现词法分析器。即:RE⟹NFA⟹DFA⟹词法分析器。
从正则表达式到词法分析器
RE → NFA
我们用 r 表示一个正则表达式,N(r) 表示由 r 构造的 NFA,我们要求 L(r)=L(N(r)),即二者表示的语言一致。
构造方法为 Thompson 构造法,其基本思想为按结构归纳:
- ϵ 是正则表达式,构造为
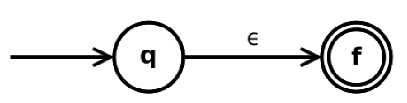 ;
;
- a∈Σ 是正则表达式,构造为
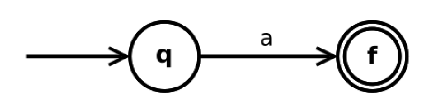 ;
;
- 如果 s 是正则表达式,则 (s) 是正则表达式,无需再次构造,N((s))=N(s);
- 如果 s,t 是正则表达式,则 s∣t 是正则表达式,构造为
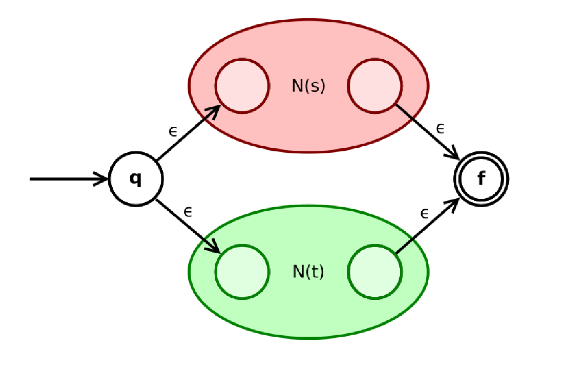 ;
;
Q:如果 NFA 的开始状态和接受状态不唯一怎么办?
A:由于 N(s) 和 N(t) 也是通过如此的构造方法得到的,只要每一步的开始状态和接受状态都是唯一的,则根据归纳假设,其开始状态和接受状态必然是唯一的。
- 如果 s,t 是正则表达式,则 st 是正则表达式,构造为
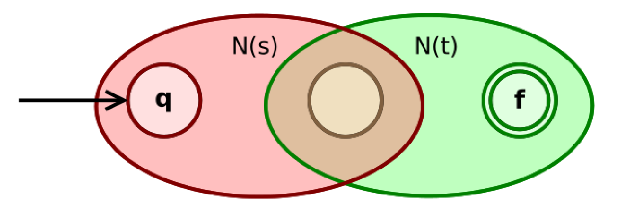 ;
;
令 Ys 为 s 的接受状态,Xt 为 t 的开始状态,只需 Ys 没有其他出弧或 Xt 没有其他入弧时,这两个状态可合并。
- 如果 s 是正则表达式,则 s∗ 是正则表达式,构造为
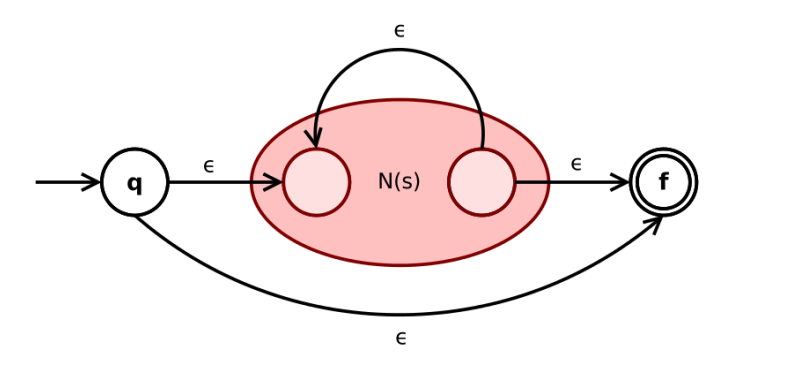 。
。
当 q 唯一时,可以与下一个空状态合并;当 f 唯一时,可以与上一个空状态合并。
这样构造出来的 NFA N(r) 有如下的性质:
- 开始状态和接受状态均唯一;
- 开始状态没有入边,接受状态没有出边;
- N(r) 的状态数 ∣S∣≤2×∣r∣,其中 ∣r∣ 表示 r 中运算符和运算分量的总和。证明显而易见,由于每一步最多加一个开始状态和接受状态,共构造 ∣r∣ 步;
- 每个状态最多有两个 ϵ-入边和两个 ϵ-出边;
- ∀a∈Σ,每个状态最多有一个 a-入边和一个 a-出边。
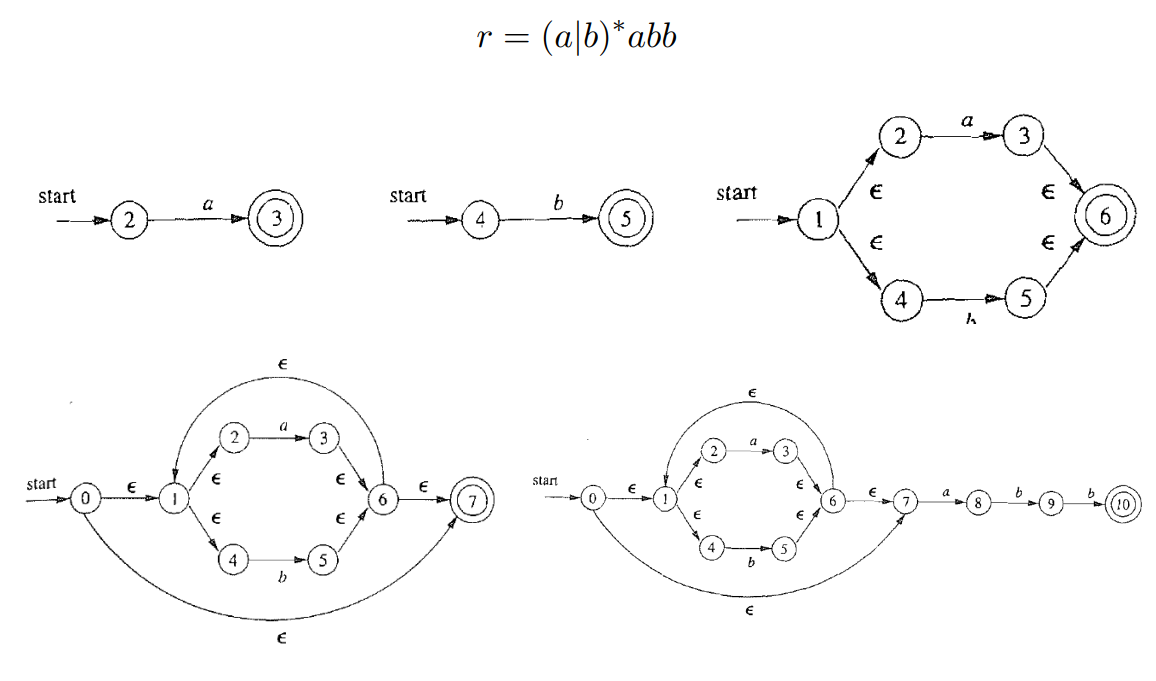
构造顺序为 a,b,a∣b,(a∣b)∗,(a∣b)∗abb。
NFA → DFA
我们用 N 表示一个 NFA,D 表示一个 DFA,我们要求 L(N)=L(D)。
我们用子集构造法来完成 N→D 的任务,思路为用 DFA 模拟 NFA。
例:将下面的 NFA 转为 DFA。
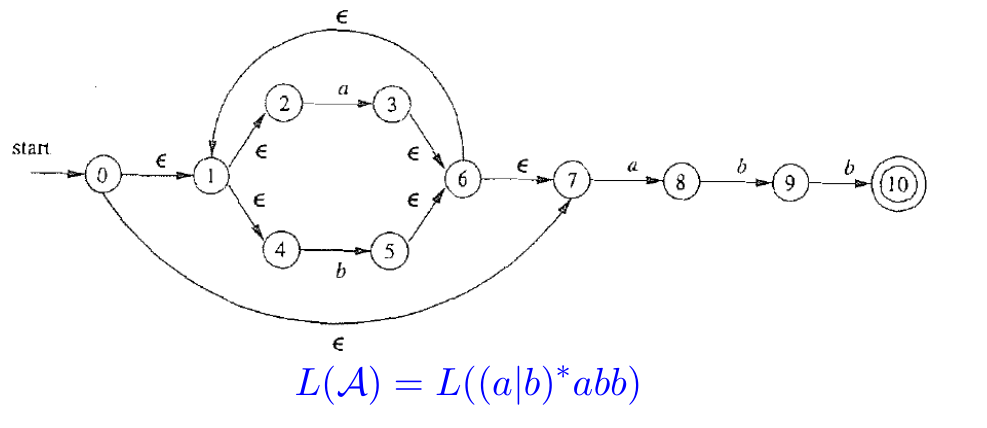
- 首先取出所有的初始状态(包括可以通过 ϵ 转移到的状态):{0,1,2,4,7},由于这些状态无法被区分,把它们整体当作 DFA 中的一个状态;
- 再看位于初始状态时会转移到什么状态:枚举初始状态集合中的每个状态,再枚举每条转移边:
- 初始状态通过 a 可以转移到 {3,8,6,7,1,2,4},其中标红的是通过 ϵ 继续转移出来的状态,把它们作为 DFA 中的一个状态;
- 通过 b 可以转移到 {5,6,7,1,2,4},把它们作为 DFA 中的一个状态。
- 不断重复上面的操作,直到转化的状态集合中包含接受状态,此时就确定了 DFA 的一个接受状态。
转化的 DFA 如下:
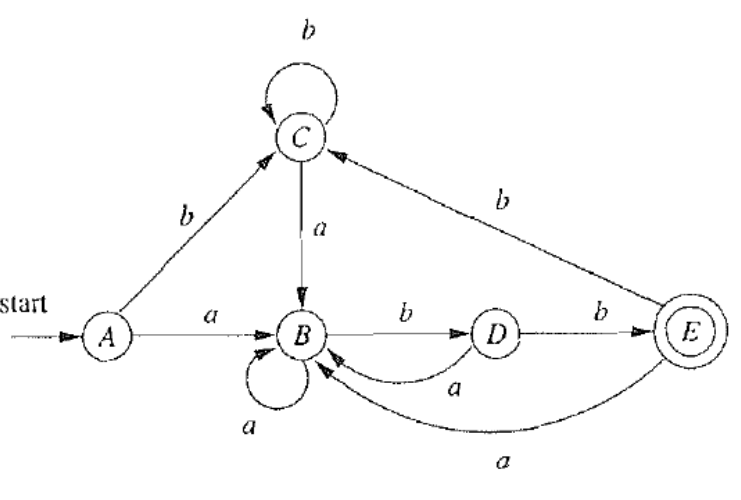

对于状态 s,把只通过 ϵ 转移可达的状态集合称为 ϵ−closure,即:
ϵ−closure(s)={t∈SN∣s→ϵ∗t}
对于一个状态集合 T,其 ϵ−closure 为
ϵ−closure(T)=s∈T⋃ϵ−closure(s)
则 DFA 上的一次状态转移
move(T,a)=s∈T⋃δ(s,a)
子集构造法就是把一个 N:(ΣN,SN,n0,δN,FN) 转化为一个 D:(ΣD,SD,d0,δD,FD),满足:
ΣDSDd0∀a∈ΣD:δD(sD,a)FD=ΣN⊆2SN(∀sD∈SD→sD⊆SN)=ϵ−closure(n0)=ϵ−closure(move(sD,a))={sD∈SD∣∃f∈FN∧f∈sD}
设 ∣SN∣=n,则 ∣SD∣=O(2n),最坏情况下 ∣SD∣=Θ(2n)。
例:构造“长度为 m≥n 个字符的仅包含 a 和 b 的字符串,且倒数第 n 个字符为 a”的 DFA。
容易写出 NFA 对应的语言:Ln=(a∣b)∗a(a∣b)n−1,并构造出 NFA:
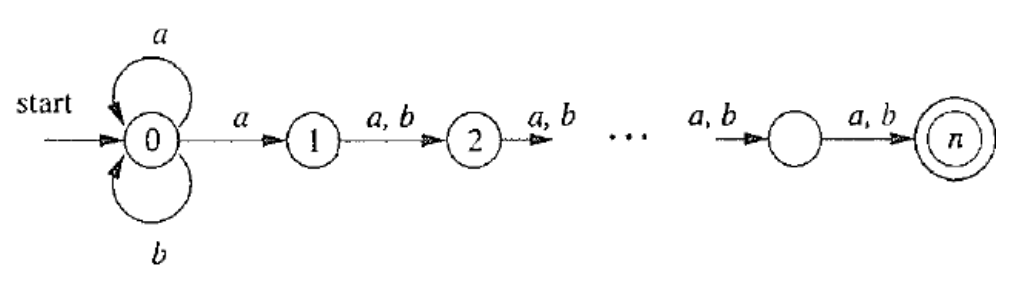
下令 n=4,便可得到一个确定的 NFA。如果对这个 NFA 用子集构造法构造 DFA,可得:
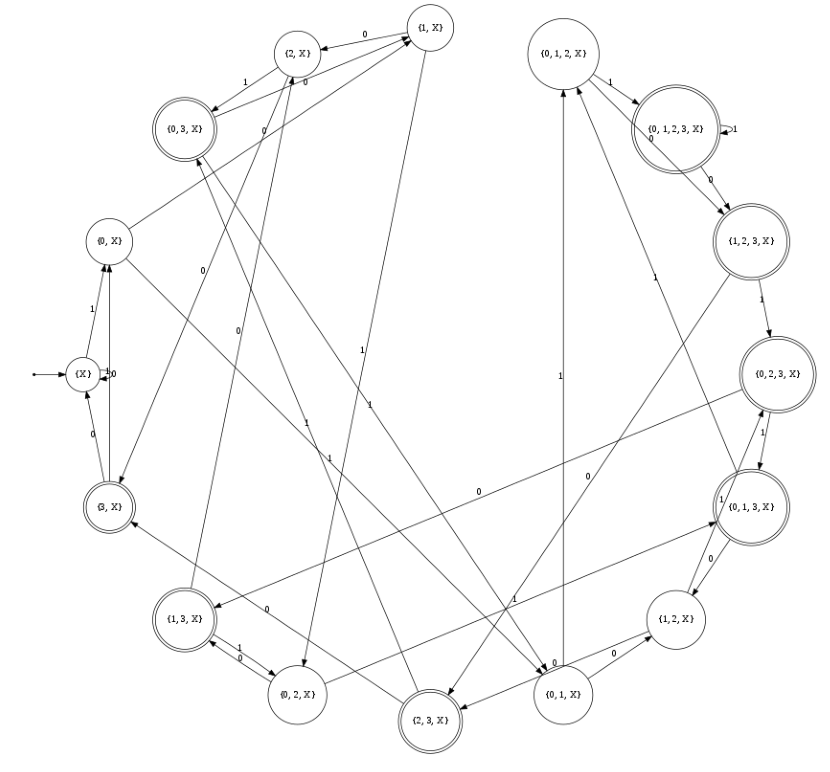
可以证明,这个 DFA 无法再被化简。
对于闭包 f−closure,我们对集合 T 不断求闭包,实际上是在做 T→f(T)→f(f(T))→⋯ 的操作,直到找到 f 的不动点(f(x)=x),即 T 不再变大。
DFA 最小化
最差情况下,NFA 通过子集构造法得到的 DFA 的状态数会出现 ∣S∣→∣2S∣−1 的变化,即指数爆炸,是不能接受的,因此需要最小化。
DFA 最小化算法被称为 hopcroft 算法,基本思想是等价的状态可以合并。
如何定义等价?非常自然地,我们认为两个状态等价,就是它们的行为是等价的,它们经过相同的转移会到达相同的状态:
s∼t⟺∀a∈Σ((s→as′)∧(t→at′))⟹s′=t′
事实上这种定义是不对的:
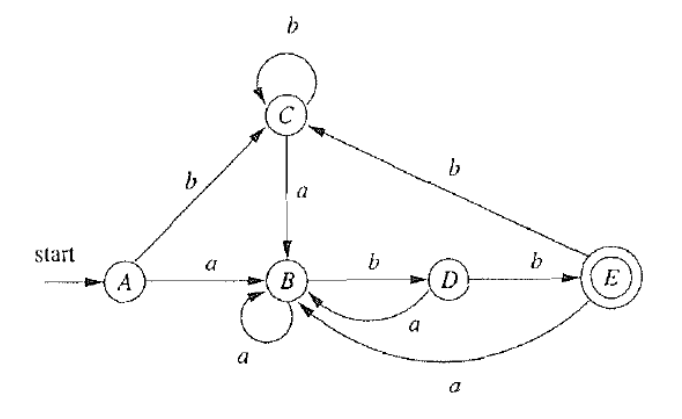
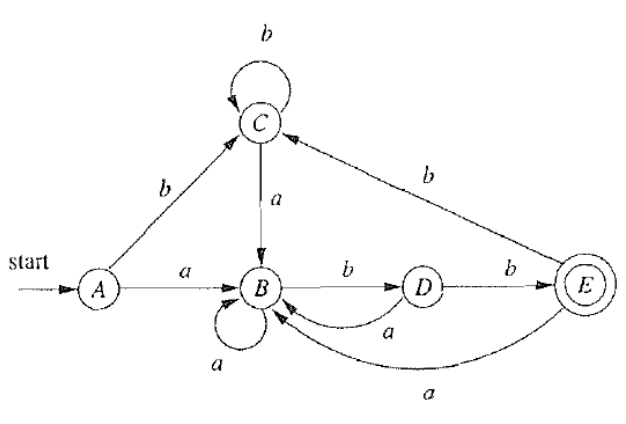
例如,A 和 E 都能通过 b 转移到 C,都能通过 a 转移到 B,但接受状态和非接受状态必然不等价!
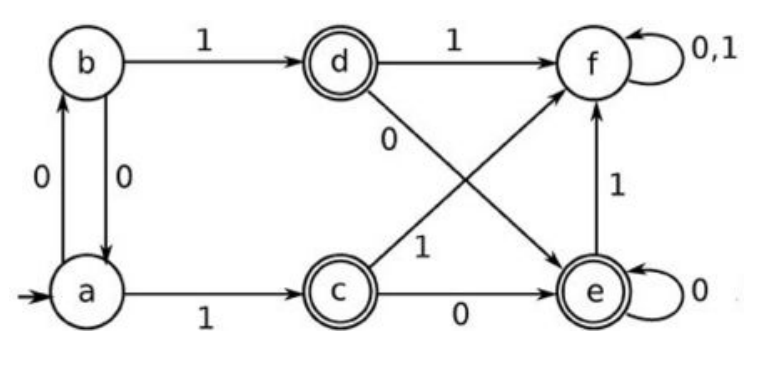
又如,按照上面的定义,可以判断 a∼b,但实际上 a∼b。
注意到上面的定义中,相同的状态过于严苛,只需要让它们都到达等价的状态:
s∼t⟺∀a∈Σ((s→as′)∧(t→at′))⟹s′∼t′
此时变成了一个递归定义,入口在哪?
正难则反!如果两个状态不等价,则有:
s∼t⟺∃a∈Σ (s→as′)∧(t→at′)∧(s′∼t′)
根据这个定义,我们可以不断地对自动机做划分,划分不等价的状态即可。
-
初始:把接受状态和非接受状态划开:Π={F,S∖F},这两类必定不等价;
- Π1={{A,B,C,D},{E}};
-
∀a∈Σ,检查每个状态集合里的状态,通过 a 转移后的状态是否在同一个状态集合中,若不在则踹出去,等待与转移相同的状态一起构造为一个集合;
-
不断迭代检查,直到所有状态集合不再变化。
- Π2={{A,B,C},{D},{E}};
- Π3={{A,C},{B},{D},{E}};
- Π4=Π3=Πfinal。
-
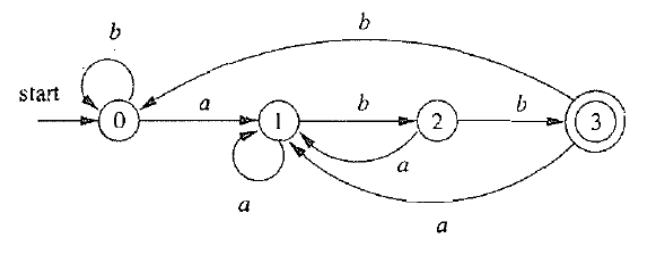
得到最终状态集合后,把每个集合中的状态合并即可:
Q:合并后是否一定是 DFA?
A:一定是。上述操作本质上是在划分等价类,一个等价类内的所有状态都会转移到同一个等价类中,合并之后仍然是 DFA。
等价类中若包含初始状态,则合并后的状态为初始状态;接受状态同理。
注意,在使用 hopcroft 算法时,必须保证状态机是一个 DFA,如果有一个 NFA,首先要向其中加入“死状态”转化为 DFA 后再做 hopcroft。
最小化结束后,只需要将进入的弧指向本集合的代表元,而不需要把离开的弧修改。因为两个状态等价的定义是:从它们开始,走相同的字符可以到等价的状态,走不同的字符可以到不等价的状态。因此,两状态等价,则他们后面走过的路径必然等价。
python 代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| class DFA():
def __init__(self, Q: set, F: set, s, relation, sigma: list):
self.Q = Q
self.F = F
self.s = s
self.relation = relation
self.sigma = sigma
def dfa_minimization(d: DFA):
P = [d.F, d.Q - d.F]
W = [d.F, d.Q - d.F]
while len(W) != 0:
A = W.pop()
if len(A) == 1:
continue
for c in d.sigma:
X = set()
for q in A:
X.add(d.relation[(q, c)])
for Y in P:
if len(X & Y) != 0 and len(Y - X) != 0:
P.remove(Y)
P.append(X & Y)
P.append(Y - X)
if Y in W:
W.remove(Y)
W.append(X & Y)
W.append(Y - X)
else:
if len(X & Y) <= len(Y - X):
W.append(X & Y)
else:
W.append(Y - X)
return P
dfa = DFA(
{1, 2, 3, 4, 5, 6, 7},
{5, 6, 7},
1,
{
(1, 'a'): 6,
(1, 'b'): 3,
(2, 'a'): 7,
(2, 'b'): 3,
(3, 'a'): 1,
(3, 'b'): 5,
(4, 'a'): 4,
(4, 'b'): 6,
(5, 'a'): 7,
(5, 'b'): 3,
(6, 'a'): 4,
(6, 'b'): 1,
(7, 'a'): 4,
(7, 'b'): 2,
},
['a', 'b']
)
F = dfa_minimization(dfa)
F = sorted(F, key=lambda x: min(x))
print(F)
print(F == [{1, 2}, {3}, {4}, {5}, {6, 7}])
|
DFA → 词法分析器
最前优先匹配:对于若干正则表达式,最前优先匹配即为从前往后第一个被匹配到的正则表达式;
最长优先匹配:对于若干正则表达式,最长优先匹配即为从前往后匹配最长的正则表达式。
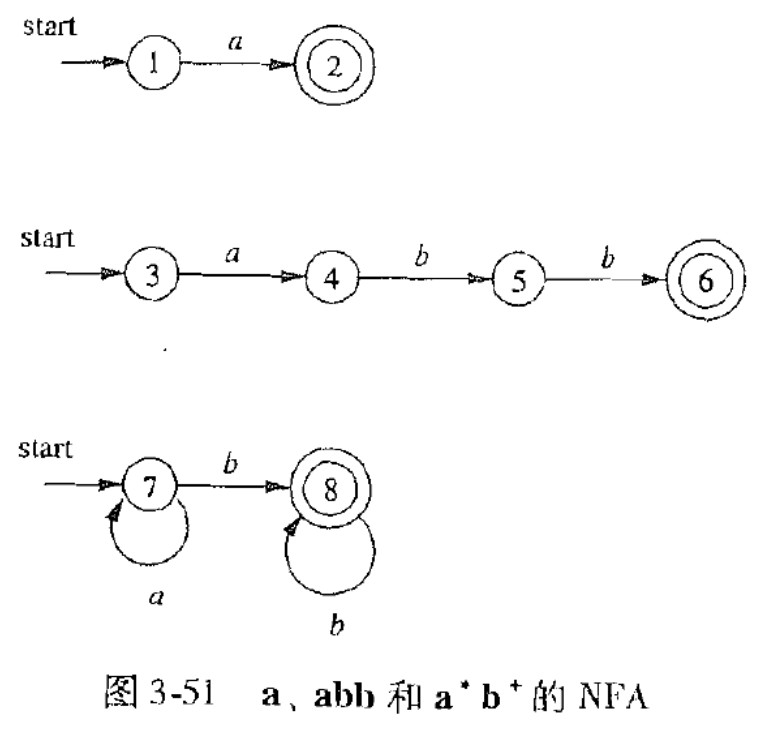
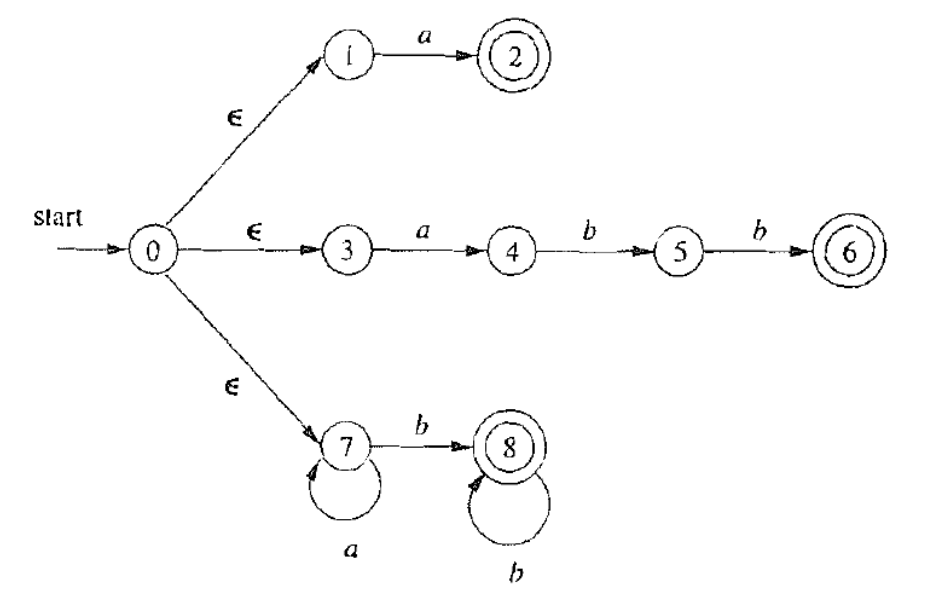
例:a,abb,a∗b+:
x=a:输入结束,接受,识别出 a;
x=abba:状态无转移,回溯成功,识别出 abb;
x=aaaa:输入结束,回溯成功,识别出 a;
x=cabb:状态无转移,回溯失败,报错 c。
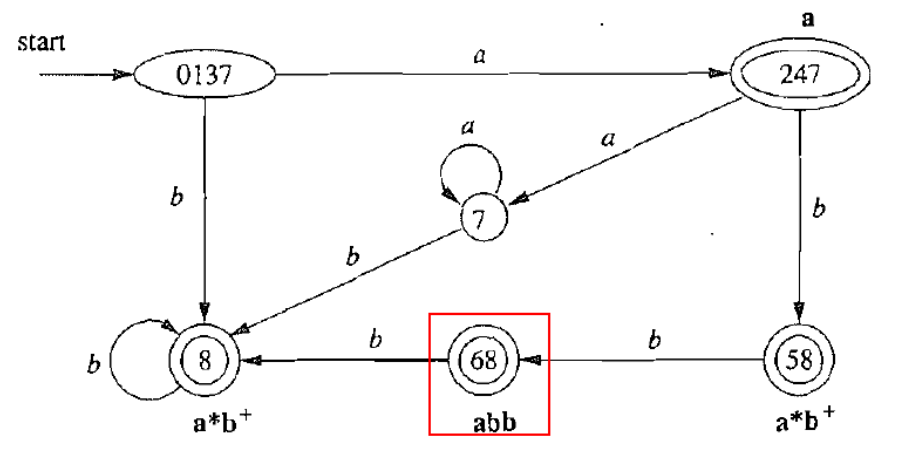
如果想把 DFA 最小化后再进行词法分析器的生成时,初始划分需要考虑不同的词法单元,把不同的词法单元对应划类:
Π0={{0137,7},{247},{8,58},{68},{∅}}。
之后再通过 hopcroft 算法进行最小化。
DFA → RE
通过类似于 Floyd 的 Kleene 构造法完成,略