语法分析
通过 ANTLR4 生成语法分析器
此处我们研究一个名为 Cymbol 的语言,是 C 语言的子集(代码附后):
这样的文法有几个问题:
-
二义性:一段程序可以有多种解释方法。
1
2
3
4
| stat: 'if' expr 'then' stat
| 'if' expr 'then' stat 'else' stat
| expr
;
|
假设此时有这样的程序:if a then if b then c else d,会出现二义性:
if a then if b then c else d;if a then if b then c else d。
这种语法歧义被称为“悬空的 else”。
如何修改这样有二义性的文法?
我们将文法修改为:
1
2
3
4
5
6
7
8
9
| stat: matched_stat | open stat ;
matched_stat: 'if' expr 'then' matched_stat 'else' matched_stat
| expr
;
open_stat: 'if' expr 'then' stat
| 'if' expr 'then' matched_stat 'else' open_stat
;
|
改造后的文法实现了第一种解释。
为什么?
- 证明改造前后接受的语句集合是相同的;
- 证明改造后的文法无二义性。
证明留做习题(
但是注意到,通过 ANTLR4 测试改造前的文法,发现同样实现的是第一种解释,并无二义性。原因是 ANTLR4 会按照从上向下的顺序分配优先级,越往上的优先级越高,所以这种实现也是正确的。
-
运算符的结合性带来的二义性:
1
2
3
4
| expr: expr '*' expr
| expr '-' expr
| DIGIT
;
|
对于此文法,1-2-3 会被解释为 (1-2)-3 或 1-(2-3):
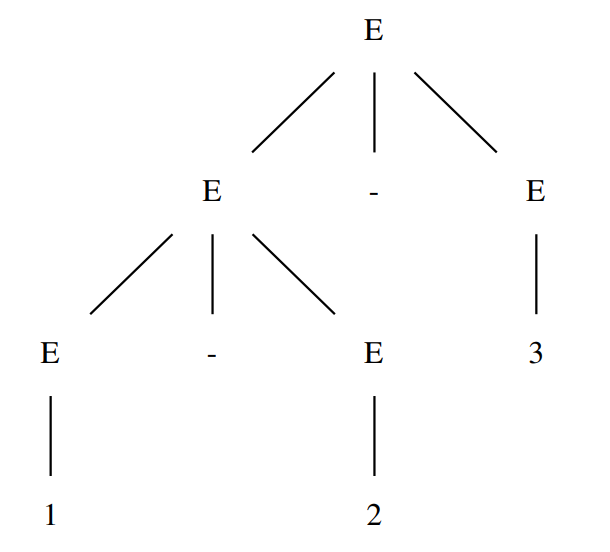
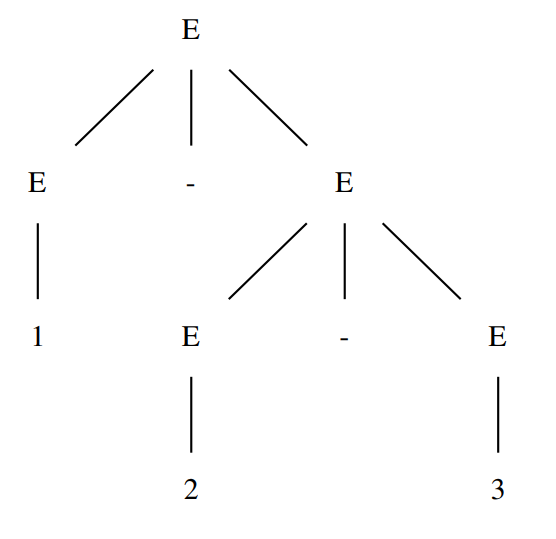
在 ANTLR4 中,如果未明确运算符是左结合还是右结合,默认左结合,即上述表达式被解释为 (1-2)-3。
如果想指定右结合,可以在语句前加入 <assoc = right>,如:
1
2
3
4
| expr: '!' expr
| <assoc = right> expr '^' expr
| DIGIT
;
|
考虑前缀运算符,这东西不带来歧义,只有一种解析方式,即右结合;后缀运算符只能左结合。
-
运算符的优先级带来的二义性:
1
2
3
4
| expr: expr '*' expr
| expr '-' expr
| DIGIT
;
|
当一个运算符优先级更高时,在解析树中的深度会更深。在 ANTLR4 中这样写已经可以处理优先级的问题,因为写在前面的优先级更高。
如果不得已非要处理这种情况,可以通过两种方法:
-
改为左递归(左结合):
1
2
3
4
5
6
7
8
9
| expr: expr '-' term
| term
;
term: term '*' factor
| factor
;
factor: DIGIT;
|
如此,对于一个语法单元 expr,只会被左侧的 expr 调用递归,这被称为左递归文法,这样限制了文法只能被左结合的方式进行解释。
由于乘号优先级更高,所以要把乘号放在右侧,等待 expr 被解释完成后再进行解释。
左递归文法:e -> e - t -> e - t - t -> ...
-
改为右递归:
1
2
3
4
5
6
7
| expr: term expr_prime;
expr_prime: '-' term expr_prime;
term: factor term_prime;
term_prime: '*' factor term_prime;
factor: DIGIT;
|
expr 表示的内容依然为 term-term-term-...,不同的是,通过引入新的语法单元 prime,expr 生成的方式为先生成一个 term,再不断生成 -term 序列,这样就是右递归文法了。
右递归文法:e -> tEP -> t - tEP -> t - t - tEP -> ...
生成函数调用图
函数调用图表示的是函数之间的调用关系。
获取函数名有两个时机:
- 在进入
functionDecl 时,可以获得当前进入的函数名;
- 在遇到
functionCall 时,即找到一个 expr 表示的是 ID '(' exprList? ')' 时,我们就可以得到被调用函数的函数名(即 ID)。
只要在图中将这两个函数名连边即可。
ANTLR4 在遍历到解析树上的每一个节点时,都会触发一个事件,用来处理相关的逻辑。
- 第一次进入一个节点时会触发
enter 事件;
- 遍历完全结束,离开节点时会触发
exit 事件。
只需要复写处理这两个事件的逻辑即可。
但注意到,访问 functionCall 时,生成的也是 EnterExpr 事件,无法具体地处理逻辑,于是需要为 ANTLR 通过 # xxx 的方式为其加标注。但是 ANTLR 只接受 0 条或 n 条标注(其中 n 为解释方法种数),于是每种解释方法都要加标注。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
| grammar Cymbol;
@header {
package cymbol;
}
prog: (varDecl | functionDecl)* EOF ;
varDecl: type ID ('=' expr)? ';' ;
/*等价于
varDecl: type ID ';'
| type ID '=' expr ';'
;
*/
type: 'int' | 'double' | 'void' ;
// type ID, type ID, ...
functionDecl: type ID '(' formalParameters? ')' block ;
formalParameters: formalParameter (',' formalParameter)* ;
formalParameter: type ID ;
block: '{' stat* '}' ;
stat : block # BlockStat
| varDecl # VarDeclStat
| 'if' expr 'then' stat ('else' stat)? # IfStat
| 'return' expr? ';' # ReturnStat
| expr '=' expr ';' # AssignStat
| expr ';' # ExprStat
;
expr: ID '(' exprList? ')' # Call // function call
| expr '[' expr ']' # Index // array subscripts
| op = '-' expr # Negate // right association
| op = '!' expr # Not // right association
| <assoc = right> lhs = expr '^' rhs = expr # Power
| lhs = expr (op = '*' | op = '/') rhs = expr # MultDiv // 这样 ANTLR 会生成一个成员类,其中有一个变量为 op
| lhs = expr (op = '+' | op = '-') rhs = expr # AddSub
| lhs = expr (op = '==' | op = '!=') rhs = expr # EQNE
| '(' expr ')' # Parens
| ID # Id
| INT # Int
;
//stat: block // 语句嵌套
// | varDecl
// | 'if' expr 'then' stat ('else' stat)?
// | 'return' expr? ';'
// | expr '=' expr ';'
// | expr ';'
// ;
//
//expr: ID '(' exprList? ')' #FunctionCall // function call
// | expr '[' expr ']' // array subscript
// // 高维数组时展开前面的 expr,从后依次到前构造
// | '-' expr
// | '!' expr
// | <assoc = right> lhs = expr '^' rhs = expr
// | lhs = expr (op = '*' | op = '/') rhs = expr
// | lhs = expr (op = '+' | op = '-') rhs = expr
// | lhs = expr (op = '==' | op = '!=') rhs = expr
// | '(' expr ')'
// | ID
// | INT
// ;
exprList: expr (',' expr)* ;
// alt+insert to generate literal tokens
EQUAL : '=' ;
SEMI : ';' ;
DOUBLE : 'double' ;
VOID : 'void' ;
LPAREN : '(' ;
RPAREN : ')' ;
COMMA : ',' ;
LBRACE : '{' ;
RBRACE : '}' ;
IF : 'if' ;
THEN : 'then' ;
ELSE : 'else' ;
RETURN : 'return' ;
LBRACK : '[' ;
RBRACK : ']' ;
SUB : '-' ;
BANG : '!' ;
CARET : '^' ;
MUL : '*' ;
DIV : '/' ;
ADD : '+' ;
EQUAL_EQUAL : '==' ;
NOT_EQUAL : '!=' ;
WS : [ \t\n\r]+ -> skip ;
ID : LETTER (LETTER | DIGIT)* ;
INT : '0' | [1-9]DIGIT* ;
fragment LETTER : [a-zA-Z] ;
fragment DIGIT : [0-9] ;
|
此时通过 gradle 执行 generateGrammarSource,在 build 文件夹中即可找到自动生成的语法分析器。
对于生成函数调用图的任务,我们只需要复写 enterFunctionDecl 和 enterCall。但是此时,CymbolListener 有许多接口,我们只需要复写其中的两个,如果直接 implements CymbolListener,我们需要复写所有的接口逻辑,如何绕过这一问题?
只需要再写一个文件,其中实现了所有接口的空逻辑,即生成文件中的 CymbolBaseListener。
上下文无关文法
上下文无关文法(Context-Free Grammar,CFG) G 是一个四元组 G=(T,N,S,P):
-
T 是终结符号集合,对应于词法分析器产生的词法单元;
-
N 是非终结符号集合;
-
S 是开始符号(S∈N 且唯一);
-
P 是产生式集合:
A∈N→α∈(T∪N)∗
左部(头部)A 为单个非终结符;
右部(体部)α 为终结符与非终结符构成的串,也可以是空串。
与之相对的是上下文有关文法(Context-Sensitive Grammar,CSG),其产生式的左部有不止一个符号,这表示其中的某个符号需要依赖于其他符号的存在才能够产生新的串。
上下文无关文法 G 定义了一个语言 L(G)。这个语言里的串从何而来?
推导:从一个非终结符开始,将某个产生式的左边替换成它的右边,直到得到终结符号。
容易注意到,每一步推导都需要选择替换哪个非终结符号,以及使用哪个产生式。
例如:E→E+E∣E∗E∣(E)∣−E∣id,我们可以得到一个推导序列:
E⟹−E⟹−(E)⟹−(E+E)⟹−(id+E)⟹−(id+id)
其中:
- E⟹−E 称为一步推导得出;
- E⟹+−(id+E) 称为经过一步或多步推导得出;
- E⟹∗−(id+E) 称为经过零步或多步推导得出。
当每一步有多个非终结符可以展开时,每次选择最左侧的非终结符进行展开时,这样的推导称为最左推导;类似地可以有最右推导。
Example:
文法 G:
ETF→E+T∣T→T∗F∣F→(E)∣id
通过最左推导得到 id+id:
E⟹E+T⟹T+T⟹F+T⟹id+T⟹id+F⟹id+id
类似地通过最右推导也可以得到 id+id。
每一次推导得到的串 α 称为文法 G 的一个句型。
如果推导得到的串 w 中所有的符号均为终结符,则称 w 是文法 G 的一个句子。
有了这些定义后,我们知道:L(G) 是文法 G 能推导出的所有句子构成的集合,即:L(G)={α∣S⟹∗α,α∈T∗}。
对于一个文法 G,我们依然关心两个基本问题:
- Membership:给定字符串 x∈T∗,x∈L(G)?即检查 x 是否符合文法 G。
- L(G) 是什么?
语法分析器的任务就是解决 Membership 问题:为输入的词法单元流寻找推导、构造语法分析树,或者报错。
Example1: 字母表 Σ={a,b} 上所有回文串构成的语言可以由如下的产生式得到:
SSSSS→aSa→bSb→a→b→ϵ
Example2: 语言 {bnamb2n∣n≥0,m≥0} 可以由如下的产生式得到:
SA→bSbb∣A→aA∣ϵ
Example3: 语言 {x∈{a,b}∗∣x 中a,b 个数相同} 可以由如下的产生式得到:
V→aVbV∣bVaV∣ϵ
最朴素的想法是 V→aVb∣bVa∣ϵ,但是这样模式过于固定,无法生成所有满足条件的串。例如以 a 开头 a 结尾的串就无法生成。
如何证明上面的产生式必定能产生我们想要的语言?
- 当产生的串 s=ϵ 时,其中的 a 和 b 的个数均为 0,且符合产生式;
- 当 s=ϵ 时,s 要么以 a 开头,要么以 b 开头:
- 当 s 以 a 开头时,只需要证明可以找到一个 b,剩下的两个子串中 a 和 b 的个数相等;
- 将 a 视作 +1,b 视作 −1,对其做前缀和,由于整个串的前缀和必然为 0,当最后一个字符为 a 时,必然有某个 b 将前缀和由正降到 0,选择这个 b 即可;
- 当最后一个字符为 b 时,它就是那个回到 0 的 b,选择这个 b 即可。
- 如此,s 就被分为了 aVbV 的形式,可以由上面的产生式得到;
- 当以 b 开头时,通过类似的方法也可以证明。
于是我们证明了 V→aVbV∣bVaV∣ϵ 就是我们想要的产生式。
Example3: 语言 {x∈{a,b}∗∣x 中a,b 个数不同} 可以由如下的产生式得到:
STUV→T∣U→VaT∣VaV→VbU∣VbV→aVbV∣bVaV∣ϵ
T 表示的是 a 更多的串,U 表示的是 b 更多的串。
Proof?
为什么不用正则表达式描述程序设计语言的语法?
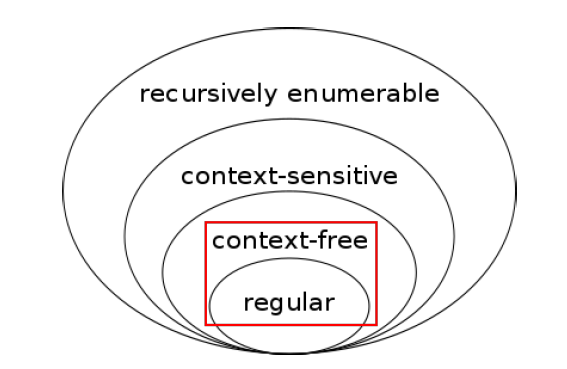
上图为不同文法的表达能力,可以发现,正则表达式的表达能力严格弱于 CFG。
如何证明?先证明 RE≤CFG,再证明 RE<CFG。
-
每个 RE 都可以先转为等价的 NFA,然后把 NFA 转为 CFG 即可。
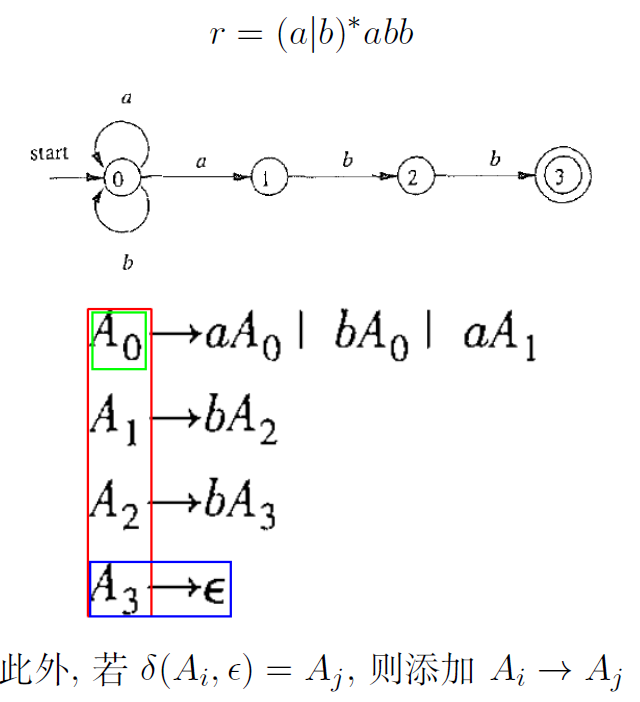
-
可以找到一个语言 L={anbn∣n≥0},其无法被正则表达式描述:
-
反证法,假设存在一个正则表达式 r,满足 L(r)=L,则存在一个有限状态自动机 D(r) 满足 L(D(r))=L,设其状态数为 k;
-
构造输入 am,其中 m>k。

-
由于 k<m,必定会存在一个接受 a 的状态被经过了两次,设其为 si,那么 si 同时接受了 ai 和 ai+j!
-
假设 si 可以经过 bi 到达接受状态,则 D(r) 可以同时接受 aibi 和 ai+jbi,出现矛盾。
-
于是我们证明了这个语言无法被正则表达式描述。
在形式化语言中有泵引理(pumping lemma)可以证明一个语言能否被正则表达式描述。