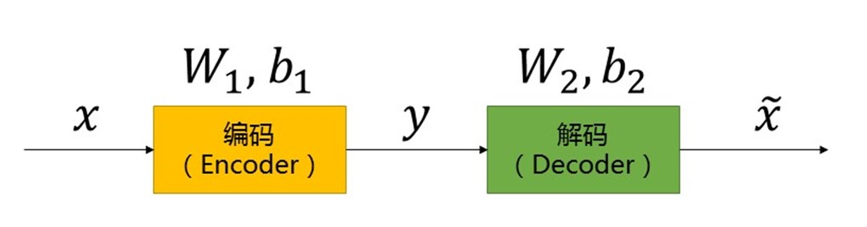
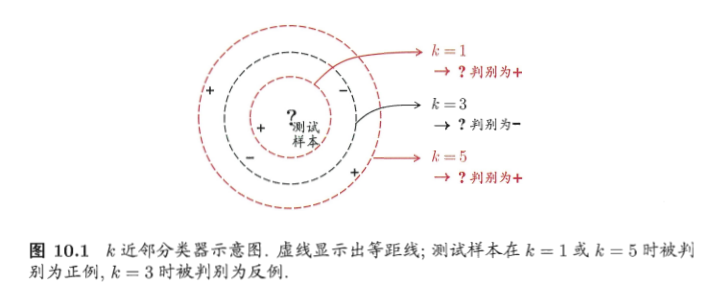
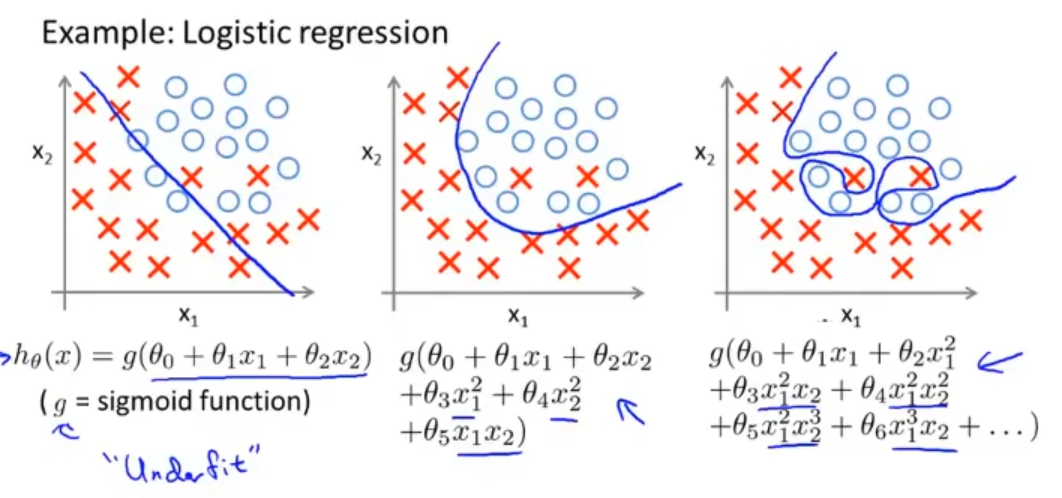
KNN 是一种常用的监督学习方法。其工作机制非常简单:给定测试样本,基于某种距离度量找出训练集中与其最靠近的 k 个训练样本,基于这 k 个邻居的信息进行预测。
通常,在分类任务中可以使用“投票法”,即选择这 k 个样本中出现次数最多的类别标记为预测结果(朴素方法直接寻找出现次数最多,值域过大可以考虑离散化,可以考虑摩尔投票法);在回归任务中可使用“平均法”,即将这 k 个样本的实值输出标记的平均值作为预测结果;还可以基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
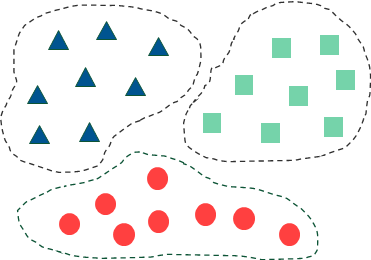
形式化地,假定样本集 D={x1,x2,…,xm} 包含 m 个无标记样本,每个样本 xi=(xi1;xi2;…;xin) 是一个 n 维特征向量,则聚类算法将样本集 D 划分为若干个不相交的簇 {Cl∣l=1,2,…,k},其中 Cl′⋂l′=lCl=∅ 且 D=⋃l=1kCl。
令 λj∈{1,2,…,k} 表示样本 xj 的簇标记,即 xj∈λj,则聚类的结果可用包含 m 个元素的簇标记向量 λ=(λ1;λ2;…;λk) 表示。